
ECS and EC2 instances
Fargate might become the new de-facto way to run containers in AWS in the not-so-distant future, and I'm excited about this. Until then, we need to make sure our EC2 hosts play nicely with ECS.
One issue you might have noticed if you've built an ECS cluster is that certain changes you make to your auto scaling groups can negatively impact the cluster, leaving you with too few running tasks, even no tasks in the worst of cases.
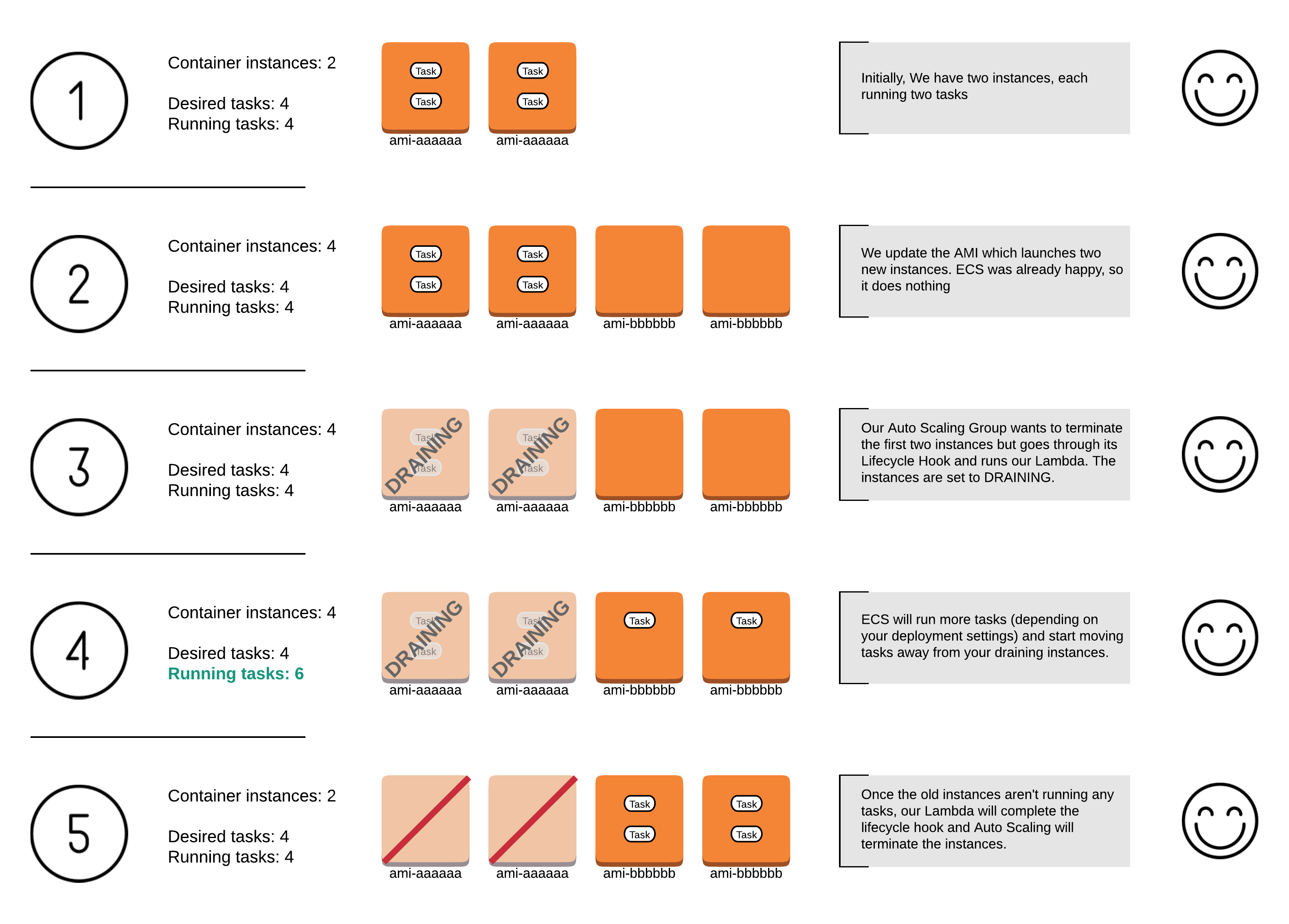
To understand why this happens, let's look at an example. Let's say you have an auto scaling group with two instances, and each of those runs two tasks...

You decide to update the AMI in your auto scaling group to a more recent version...

You're relying on auto scaling group rolling updates to do the job: you've set it up so it will first launch two new instances and, only when those are ready, it terminates the two old instances you want to replace. It sounds good, and yet you've had about a minute's worth of downtime... how could this be?

Let's look at this from ECS's perspective. The number of desired tasks for your ECS service is four (ideally two per instance). You have two instances, each running two tasks. ECS sees the two new instances when they register with the cluster. However, it does nothing as it's already running the four tasks you've told it to run. Soon after this, the two old instances (the ones running the tasks!) go away. At this point, you've got two instances (the new ones) and no running tasks. ECS does its best to fulfill the desired task count and promptly launches two tasks in each of your new instances. However, it's too late if you wanted zero downtime, as there's been a short duration where you were running no tasks.
We should be able to do better than that, and indeed we can!
Enter instance draining
In early 2017, AWS announced Container Instance Draining. This is a container instance state that basically tells ECS "I don't want any new tasks in this instance, and I need you to move any running tasks elsewhere". This sounds exactly like what we're after.
If you were to manually start an EC2 instance and register it with the ECS cluster, then you could mark an older instance as DRAINING in ECS and wait for the magic to happen. Once your old instance isn't running any tasks anymore, you can safely terminate it.
In a scenario with auto scaling groups, however, this needs to happen automatically. Auto Scaling groups provide a mechanism called Lifecycle Hooks which allows you to perform any necessary actions when instances are about to launch or terminate. In our case, we want the auto scaling group to notify us when it wants to terminate an instance and wait until we're done cleaning it up before it actually terminates it. We can use an SNS topic for this notification, and a Lambda function as the topic subscription target. Our Lambda function will run every time an instance in our auto scaling group is about to be terminated.

As soon as the draining function runs, we send a request to the ECS APIs to change the container instance state to DRAINING. We then need to wait for the instance to be running zero tasks before we can tell Auto Scaling that it can proceed with terminating it. AWS has recommended running the Lambda function over and over again until the instance is good to go, but we think we have a more efficient way: we're going to create a CloudWatch Events Rule that listens for ECS task state changes. We're going to tell it to run our Lambda function every time a task transitions to the STOPPED state. Our function checks to see if the instance is running any tasks, and if it isn't, it will complete the lifecycle action, essentially giving the Auto Scaling service a green light.

There you have it. Now we can replace our EC2 instances without incurring any downtime. Here's another diagram with the new scenario (click to enlarge):
Enough chit chat... Show me the code!
Let's do a quick recap of all the building blocks that make this solution. We need:
- An ECS cluster with at least a service, and some running tasks
- An auto scaling group with instances that register themselves with ECS
- A lifecycle hoook in our auto scaling group for the autoscaling:EC2_INSTANCE_TERMINATING transition that sends notifications to an SNS topic
- The SNS topic itself
- A CloudWatch Events Rule that listens for tasks transitioning to the STOPPED state
- A Lambda function that is invoked by both the SNS topic and the CloudWatch Events Rule above
That sounds like a handful, so let me give you a full running example. You can go ahead and launch this CloudFormation template  . Once you've entered the required parameters and your stack is ready, you can play with your auto scaling group: downscale it to see some instances go away, for example. Look at the instance state in ECS and watch some instances go through the DRAINING state before they disappear, as the remaining instances run new tasks to replace the ones that are about to vanish.
. Once you've entered the required parameters and your stack is ready, you can play with your auto scaling group: downscale it to see some instances go away, for example. Look at the instance state in ECS and watch some instances go through the DRAINING state before they disappear, as the remaining instances run new tasks to replace the ones that are about to vanish.
Feel free to use the provided CloudFormation template as a base for your ECS clusters. Here's the code for the Lambda function.
We hope you'll find this resource useful. Don't hesitate to contact Osones for your ECS projects!
Igor AIESTARAN
Découvrez les derniers articles d'alter way


