
Retrouvez également les premiers jours de conférence et la deuxième Keynote.
Continuons donc notre __tour d’horizon complet en 5 minutes, et en français ! __

Le moment tant attendu : la première Keynote !
Si AWS ne cesse de faire des annonces - les lecteurs assidus du blog Osones le savent - et que ces dernières n’ont pas perdu en intensité ces dernières semaines, le Re:Invent reste véritablement LE RDV impressionnant qui en met plein les yeux.
L’an passé se sont succédées près de 20 annonces réparties équitablement sur les deux premières Keynotes. Et comme l’an passé, nous avons regroupé ici même les annonces de la première Keynote, pour votre plus grand plaisir !
Comme pour le résumé des nouveautés que vous retrouverez chaque lundi sur ce blog, la promesse est simple : __un tour d’horizon complet en 5 minutes (un peu plus pour cette fois !), et en français ! __
Les 40 000 personnes s'installent pour la grande Keynote de l'AWS #reInvent 2017 ! Suivez le live ici ! #aws #cloud #AWSreinvent2017 pic.twitter.com/j235oPF9rR
— Osones 🇫🇷 (@osones) 29 novembre 2017
Les nouveautés autour du Compute :
- Le bare-metal arrive chez Amazon
Amazon vient d'annoncer la disponibilité en bêta publique d'instances bare-metal. Il n'y a pour l'heure qu'une configuration de disponible, mais Amazon a déjà annoncé que d'autres configurations suivront.
Le modèle disponible est une configuration très puissantes puisque cette i3.metal offre deux Intel Xeon E5-2686v4 @ 2.3 GHz (36c/72t), 512Go de RAM, 15.2To de stockage NVMe avec une connexion réseau de 25Gbps.
Ces instances profitent de toutes les fonctionnalités classiques des instances EC2 : security groups, elastic load balancing, auto scaling, VPC …
Announcing Bare Metal Instances to allow customers to run non-virtualized workloads with direct access to hardware #reInvent pic.twitter.com/6enPCs4ds5
— AWS re:Invent (@AWSreInvent) 29 novembre 2017
Lors de la keynote Tuesday Night Live, Amazon a expliqué que les instances bare-metal étaient demandés par les clients notamment pour :
- Faire tourner un cluster VMware chez Amazon, en utilisant la distribution non-modifiée de VMware ; c’est d’ailleurs l’aide de cette innovation qu’Amazon peut proposer le VMware Cloud sur AWS.
- Disposer de performances maximales, en se passant de la couche de virtualisation
- Accéder aux compteurs de performances CPU hardware
Afin de proposer ces instances bare-metal tout en profitant de l'écosystème EC2 (VPC, security groups, ...), Amazon a développé des ASICs pour offloader ces fonctions qui traditionnellement étaient fournies par des processus qui tournaient à côté de l'hyperviseur. Ces ASICs ont été développés avec l'aide des compétences de Annapurna Labs, qu'Amazon a acquise en 2015 au sein du projet Amazon Nitro.
- Amazon S3 et Amazon Glacier Select
Inutile de présenter Amazon S3, le service de stockage objet d’#AWS, ou Amazon Glacier, son pendant pour le stockage à froid. Ces deux services ont désormais une nouvelle feature : S3 Select et Glacier Select.
Ce que vous ne savez peut-être pas encore, c’est qu’il est possible d’effectuer des requêtes SQL sur Amazon S3 : via Amazon Athena, Amazon Redshift, Amazon EMR, ou avec des solutions tierces comme Cloudera ou DataBricks.
Avec Amazon S3 Select, ces requêtes SQL - à partir de fichiers CSV, JSON, ou GZIP - seront jusqu’à 5 fois plus rapides ! Ce qui n’est pas sans incidence sur les coûts associés. Le secret : S3 Select vous permettra de ne prendre que les données dont vous aurez directement besoin.
Dans un fichier contenant 300 lignes de texte par exemple, il suffira d’utiliser “s3select” couplé à un ou plusieurs mots clés pour récupérer les données qui vous intéressent. Utile lorsque l’on sait qu’Amazon S3 peut stocker des fichier allant jusqu’à 5 terabytes !
Ce service fonctionne aussi avec Amazon Glacier. L'exécution de la requête restera cependant dépendante du temps d’extractions de données (d’une minute à 12 heures, en fonction de l’option que vous aurez choisie et payée pour votre Coffre-Fort Glacier).
Les services de stockage #AWS #S3 et #Glacier s'améliorent avec "Select", pour affiner la recherche de données 🕵️♀️#AWSreinvent2017 #AWSreInvent pic.twitter.com/bapyy8TmB3
— Osones 🇫🇷 (@osones) 29 novembre 2017
Encore une fois, AWS arrive à nous surprendre en améliorant des services historiques !
- Deux nouvelles familles d’instances : M5 et H1 !
De nouveaux types d’instances sont présentées d’emblée : la nouvelle génération d’instance “general purpose” M5, et la famille H1 orientée pour le stockage Big Data (de gros MapReduce ou des Apache Kakfa. Rien de particulier à ajouter 😁
Les nouveautés concernant les Bases de Données :
Pas de jaloux pour ce #ReInvent2017 : 2 nouveautés pour #AWS #Aurora, et 2 pour #DynamoDB 😎 pic.twitter.com/jpCMvqWNYg
— Osones 🇫🇷 (@osones) 29 novembre 2017
- Amazon Aurora propose du Multi-Master !
Amazon frappe un très, mais alors un très très grand coup. Attention : ça va faire mal !
Aurora, c’était déjà top pour la possibilité d’ajouter des Read Replica à la volée, très rapidement, et sans se baser sur les mécanismes de réplications des moteurs de bases de données (MySQL ou PostgreSQL). Et, depuis peu, on peut même autoscaler ces read-replicas
Pour “scaler” les écritures, pas d’autre choix que d’augmenter la capacité du noeud master (plus de CPU, plus de RAM)... Mais ça, c’était avant !
Car aujourd’hui, Amazon nous offre le multi-master ! Oui ! Le multi-master. Beaucoup se sont cassés les dents là dessus. On connaît MySQL Galera. D’aucuns disent que dans Galera, il y a “Galère”, et comme disait Géronte, “mais que diable allait il faire dans cette galère ?”
On connaît la fiabilité des services Amazon. Gageons donc que cette fonctionnalité “multi-master” d’Aurora soit à la hauteur. Il nous faut donc tester tout ceci, et voir quelles sont les éventuelles limitations du service.
On passe désormais aux bases de données : #Amazon #Aurora propose du Multi-Master! En preview, le service est prévu pour 2018#AWSreinvent2017 #AWS pic.twitter.com/oByXlrP8iP
— Osones 🇫🇷 (@osones) 29 novembre 2017
- Amazon Aurora propose une version Serverless !
DynamoDB, c’est chouette, car nul besoin de provisionner des serveurs, de penser à la RAM ou au CPU. C’est un service totalement managé. On s’occupe juste de nos données. Et c’est encore plus vrai depuis que l’autoscaling des capacités existe. Le “problème”, c’est que DynamoDB, … c’est du NoSQL. Et quand on veut faire du relationnel, ce n’est pas vraiment adapté.
Autre nouveauté majeure pour #AWS #Aurora : #Aurora #serverless! https://t.co/lNHK0C8NHQ pic.twitter.com/6VvaFZNt5g
— Osones 🇫🇷 (@osones) 29 novembre 2017
Qu’à cela ne tienne, AWS invente Aurora Serverless. Pardon ? Oui, Serverless ! Donc comme pour DynamoDB, on pourra maintenant utiliser Aurora, comme avant, mais sans se soucier de l’infrastructure sous-jacente. Le service fournit un endpoint, les données sont stockées dans le moteur de stockage d’Aurora (comme avant), et le reste scale automatiquement en fonction de la charge.
Parfait pour un environnement de pré-production par exemple : la nuit, il ne se passe rien. Et bien rien ne tourne. Seul le volume de stockage des données sera donc facturé. Parfait également pour les environnements ayant une charge peu prédictible ou très variable.
Là encore, Amazon frappe un très gros coup. Il va devenir difficile de ne pas craquer pour Aurora. Il nous reste plus qu’a tester tout ceci, pour pouvoir vous faire un retour plus détaillé.
- DynamoDB Global Tables : la réplication multi-région enfin à portée ?
Lors de nos rendez-vous clients, lorsque l’on présente nos solutions d’architecture, nos clients nous challengent souvent sur la possibilité de faire du multi-région. Notre réponse est toujours la même :
“Le multi-région n’est pas compliqué en soit. Il suffit de répartir les ressources sur les différentes régions, et de laisser Route53 faire la géo-distribution… Mais, en revanche, c’est tout de suite beaucoup, beaucoup plus complexe pour les bases de données.”
En effet, le multi-région sur les données est un vrai problème “dur”, comme disent les informaticiens. Autant répliquer des données en lecture sur plusieurs régions peut se faire, autant la possibilité d’écrire à différents endroits de la planète… est très complexe.
Et… pourtant, Amazon ce matin nous annonce une nouvelle fonctionnalité dans DynamoDB : DynamoDB Global Tables.
Comme son nom l’indique, on peut maintenant en 3 clics (ou peut être moins, je n’ai pas compté), créer une table DynamoDB répartie sur plusieurs régions, en mode multi-master. Donc aussi bien pour les lectures que pour les écritures !
- DynamoDB “Backup and Restore”
Là encore, en rendez-vous clients, lorsque nous “poussons” DynamoDB, la question des sauvegardes revient souvent. Et il faut bien l’avouer, sauvegarder des données stockées dans Dynamo était jusqu’à présent assez pénible.
Soit on faisait un script faisant régulièrement un gros SCAN de toutes les tables et stockait le résultat dans S3, soit on se basait sur le service Amazon DataPipeline pour faire à peu près la même chose. Le problème avec cette solution est que d’une part c’est lent (pour peu qu’il y ait beaucoup de données) et surtout, la sauvegarde impacte la performance globale… ce qui n’est pas fou fou.
Amazon nous offre donc ce matin une nouvelle fonctionnalité dans DynamoDB : Backup & Restore.
En un clic (ou un appel API), on peut désormais générer une sauvegarde complète d’une table, en une fraction de seconde, sans aucun impact sur les performances, et sans downtime. L’équivalent des snapshots RDS donc.
A venir très bientôt également, la possibilité de faire du “point-in-time” recovery.
Que du bon ! On aime quand Amazon ne se contente pas d’inventer de nouveaux services, mais continue, chaque jours à améliorer (et de quelle manière !) les services existants.
Well done AWS !
Les nouveautés concernant les conteneurs
On en fait beaucoup chez Osones : les conteneurs sont un moyen puissant pour les développeurs de développer, packager et déployer des applications. Avec des centaines de milliers de clusters ECS, AWS n’est pas en reste dans le domaine. Après cette conférence, les attentes les plus communéments partagées trouvent réponse !
[#AWS #ReInvent2017] Deux noms à retenir pour les conteneurs : Amazon EKS pour #Kubernetes et AWS #Fargate qui propose des conteneurs "managés" dans le #Cloud pic.twitter.com/KgjUDwwG9X
— Osones 🇫🇷 (@osones) 29 novembre 2017
- Amazon Elastic Container Service for #Kubernetes (EKS)
Vous en rêviez, ils l’ont fait ! Une fois de plus, AWS répond aux attentes de leurs clients : d’après la Cloud Native Computing Fondation, 63% des workloads Kubernetes tournent sur AWS !
Autant dire que l’arrivée d’Amazon Elastic Container Service for Kubernetes (Amazon EKS) était une évidence, dont l’absence aurait laissée un gouffre sans fond
Que dire de plus, si ce n’est qu’EKS est un service managé pour Kubernetes ? Et bien sachez qu’EKS utilise la version upstream du logiciel Opensource Kubernetes, ce qui est fort appréciable : tous les plugins et outils de la communauté sont donc utilisables, et le service ne souffre d’ aucune adhérence particulière.
Le service est encore en beta pour le moment.
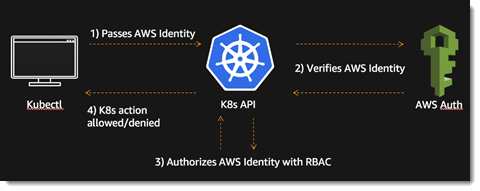
Lors d’une conférence de présentation du produit, le product manager d’EKS que son équipe contribue massivement au projet.
- AWS Fargate, du Conteneurs as a Service
A en croire l’applaudimètre dans l’immense salle du Venitian ou se déroule cette Keynote, Fargate est une énorme annonce ! Les faits : ECS est un très bon service pour déployer et gérer des conteneurs Docker sur Amazon. Mais il faut continuer à gérer les instances EC2 (et donc les patches, l’autoscaling, etc.) en plus des conteneurs.
Autrement dit, la couche “conteneurs” se rajoute à la couche “EC2”, ce qui complexifie grandement les infrastructures : deux niveaux d’autoscaling, deux niveaux de ressources, etc.
Avec Fargate, on peut faire fi de ce deuxième niveau ! En effet, Fargate offre la possibilité magique de pouvoir déployer directement des conteneurs dans le cloud. Oui, directement dans le cloud. Pas sur un cluster d’instances EC2, non, directement.
Spécifiez le CPU et la mémoire voulue parmi un ensemble de 50 configurations, créez l’image de votre conteneur, et VOILA :)

Disponible dans la région US East, Fargate supportera EKS courant 2018. Question tarif, il vous en coûtera $0.0506 par vCPU et par heure, et $0.0127 par GB de mémoire et par heure.
Les nouveautés autour du Machine Learning :
Malgré des décennies d'investissement et d’améliorations, le Machine Learning reste extrêmement complexe. Ce qui en fait un BuzzWord trop entendu, et assez peu vu (non, un chatbot n’est pas du Machine Learning 🤖). C’est contre ce constat que travaille AWS.
Les entreprises comme les développeurs cherchent donc des solutions simples et rapides. C’est donc ce que fera AWS, qui annonce cette année quelques nouveaux services. Ouf !
Nous passons désormais au #MachineLearningavec #Amazon #Sagemaker, qui veut diminuer la complexité de ces nouveaux usages #ReInvent2017 #AWS pic.twitter.com/7r0BRdbkGu
— Osones 🇫🇷 (@osones) 29 novembre 2017
- Amazon SageMaker
Amazon SageMaker à pour objectif de simplifier la construction de modèles de Machine Learning, et de permettre à ces modèles d’apprendre rapidement grâce à une connectivité accrue aux données.
Incluant 10 des modèles de machine learning les plus courants, le service est optimisé pour ces algorithmes et framework pré-installés, les rendant jusqu’à 10 fois plus rapides que sur d’autres plateformes. Apache MXNet et TensorFlow, pour ne citer qu’eux, comptent parmi les framework bénéficiant de ce travail d’optimisation.
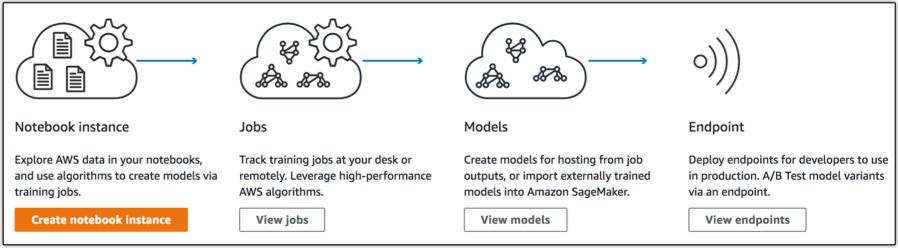
Plus d’informations sur page officielle de SageMaker
- Amazon DeepLens, une caméra vidéo pour le Deep Learning
Amazon DeepLens a pour vocation d’aider les développeurs à apprendre les techniques de Machine Learning. Conçue pour une prise en main autour de 10 minutes, la caméra est programmable et bénéficie de tout un tas d'exercices et de tutos pour une montée en compétence simple et efficace. Elle devrait être disponible à l’achat courant 2018.
- Amazon Comprehend, Amazon Translate et Amazon Transcribe
Après Amazon Polly, Amazon Lex et Amazon Rekognition annoncés l’an passé (permettant respectivement de convertir le texte en voix, de comprendre le sens de phrases et de reconnaître des images), trois nouveaux services complètent aujourd’hui la suite de services de ML.
Amazon Comprehend permet d’extraire d’un texte les idées générales. Se basant sur le “natural language processing (NLP)”, autrement appelé en français “Traitement automatique du langage naturel”, amazon Comprehend va identifier des entitées, des phrases clés, des sentiments, des sujets, et toute autre information permettant d’oagniser automatiquement vos documents, qu’ils soient dans Amazon S3 ou dans Glue.
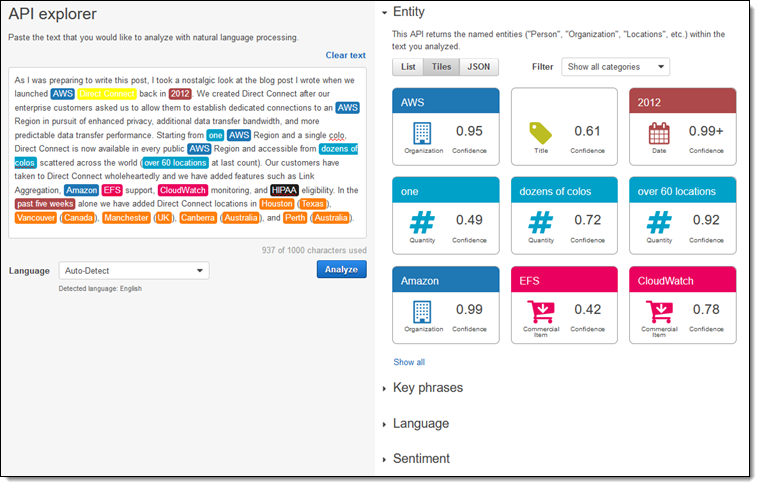
Amazon Translate permet comme son nom l’indique de traduire des textes.
Amazon Transcribe enfin permet de faire du “speech to text”. Capable de transcrire des conversations téléphoniques, d’accepter du vocabulaire custom, et prochainement capable de distinguer plusieurs voix, Amazon Transcribe est idéal pour améliorer le support client ou pour sous-titrer vos vidéos. Il ne sera disponible au début qu’en anglais et en espagnol, mais les autres langues devraient suivre.
Les nouveautés pour l'IoT
Cette année l'IOT a également eu son lot d'annonce. Que ce soit pour l'analyse, la gestion ou la sécurité.
- AWS IoT Analytics
Vous allez pouvoir construire des dashboard pour pouvoir analyser et monitorer les données qui seront transmis par vos différents objets connectés. Cette fonctionnalité sera intégré au produit déjà existant qui est Quicksight.
- AWS IoT Device Defender
IoT Device Defender comme son nom l'indique, ce service va vous permettre d'auditer, surveiller et alerter sur le comportement des différents objets et permettre de détecter quand ceux-ci sont compromis.
- AWS IoT Device Management
La troisième annonce est IoT Device Management. Vous allez maintenant pouvoir gérer une flotte d'objets importantes facilement à l'aide de plusieurs fonctionnalités comme le templating, la gestion par groupe, le monitoring ou encore la gestion distante.
- Amazon FreeRTOS
Cette dernière annonce n'est pas un service mais un système d'exploitation pour l'IoT. Celui-ci est disponible en open source, ce qui ravira bon nombre de personnes. Ce système se base sur un composant déjà connu dans le domaine qui est le noyau FreeRTOS, et a ajouté un certain nombre de fonctionnalité pour faciliter l'exploitation des objets IoT : des librairies pour des accès local ou cloud la sécurité la mise à jour en direct (bientôt)
- Le tacle BONUS de la keynote :
En parlant du rythme d'innovation du #Cloud,#AWS ose la comparaison ! Saurez-vous reconnaître ces vendors ? 🙊🙉🙈#AWSreinvent #cloud #AWSreinvent2017 https://t.co/yL1k5R8B6m pic.twitter.com/H2p9svfm5L
— Osones 🇫🇷 (@osones) 29 novembre 2017
C'était l'essentiel de cette première keynote, retrouvez nous demain pour la suite !
L’équipe Osones
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025



