Authors : Alterway

Cet article est le second article d'un tour d'horizon sur les bases de données NoSQL. Le premier article portait sur les bases Document. Nous allons voir maintenant de façon synthétique ce qu'offrent les bases en Graphe telle que Neo4j et en quoi elles diffèrent des bases SQL classiques. Les principes que l'ont retrouve dans les bases Documents sont les suivants :
Une notion d'adjacence, de relation :
C'est ici la particularité de ces bases de données. Les données sont stockées dans des noeuds typés (Person, Movie), et sont indépendants les uns des autres, même s'ils sont du même type. Ces noeuds sont liés entre eux par des relations typées. Ainsi une Person peut être liée à un Movie de plusieurs manières, comme en étant acteur du film, producteur, réalisateur etc ... Dans des cas de calculs mathématiques, on peut très bien utiliser les relations pour aboutir à un graphe pondéré, chaque relation ayant comme valeur un poids.
Un schéma de données déterminé, mais libre :
Chaque Noeud a un format particulier selon son type, comme une ligne d'une table SQL classique. Cependant, chaque noeud pour avoir un Label en plus de son type. Par exemple, un noeud Person pour avoir un label Actor, permettant de mieux cibler des Person lorsque l'on joue une requête. Ces labels peuvent être multiple sur chaque noeud, et peuvent être utilisé de façon temporaire pour exprimer un status. Une Person pourra avoir le label Malade, ou Heureux. Les requêtes pour récupérer de la donnée sont différentes des requêtes classiques SQL. Le langage de requétage est ici Cypher :
{{< highlight sql >}} MATCH (tom:Person {name: "Tom Hanks"})-[:ACTED_IN]->(tomHanksMovies) RETURN rom, tomHanksMovies {{< /highlight >}}
Ici, nous requêtons des informations sur la Person ayant l'attribut name égal à "Tom Hanks", que nous variabilisons à "tom" en début de parenthèse. Cette Person est liée à un ensemble d'éléments que nous appelons ici "tomHanksMovies". La relation qui va lier tom et tomHanksMovies doit être de type "ACTED_IN". Le résultat sera alors le graphe suivant : 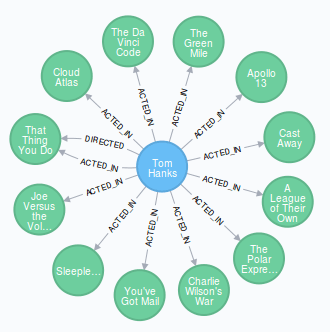 Il est également possible de présenter les données récupérées en tableau (Ici nous requêtons les acteurs ayant jouer dans les mêmes films que Tom Hanks) :
Il est également possible de présenter les données récupérées en tableau (Ici nous requêtons les acteurs ayant jouer dans les mêmes films que Tom Hanks) :
{{< highlight sql >}} MATCH (tom:Person {name: "Tom Hanks"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors) RETURN coActors.name {{< /highlight >}}
 Enfin, prenons une dernière requête un peu plus compliquée. Nous récupérons tous les acteurs ayant joué avec Tom Hanks, et à partir de cette liste nous cherchons ceux qui ont également joué avec Tom Cruise.
Enfin, prenons une dernière requête un peu plus compliquée. Nous récupérons tous les acteurs ayant joué avec Tom Hanks, et à partir de cette liste nous cherchons ceux qui ont également joué avec Tom Cruise.
{{< highlight sql >}} MATCH (tom:Person {name:"Tom Hanks"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors), (coActors)-[:ACTED_IN]->(m2)<-[:ACTED_IN]-(cruise:Person {name:"Tom Cruise"}) RETURN tom, m, coActors, m2, cruise {{< /highlight >}}
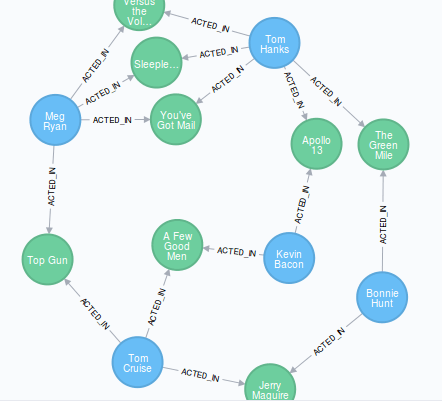 L'utilisation d'une base de données en Graphe est spécifique à des besoin de performances lors de relations nombreuses entre différents éléments d'une base. Il peut être utilisé, par exemple, pour lier des personnes par leurs affinités sur des sites de rencontre (avec des noeuds d'affinités, et les relations entre les noeuds "personne" et "affinité" étant un degrès d'affinité).
L'utilisation d'une base de données en Graphe est spécifique à des besoin de performances lors de relations nombreuses entre différents éléments d'une base. Il peut être utilisé, par exemple, pour lier des personnes par leurs affinités sur des sites de rencontre (avec des noeuds d'affinités, et les relations entre les noeuds "personne" et "affinité" étant un degrès d'affinité).
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025



