Authors : Alterway

Troisième et dernier article d'un tour d'horizon sur les bases de données NoSQL. Les premiers articles portaient sur les bases de données de type :
Nous allons voir ce qu'offrent les bases en Colonne telle que Cassandra et en quoi elles diffèrent des bases SQL classiques. Les principes que l'ont retrouve dans les bases en Colonne sont les suivants :
Stockage valeur/clé :
Dans les bases de données en Colonne, les lignes de données sont stockées différemment que dans les bases de données classiques. Ces dernières stockent les données en ligne de la façon suivante :
{{< highlight bash >}} 001:Doe,John,33; 002:Smith,Joe,34; 003:Doe,Jane,32; {{< /highlight >}}
Là où une base de donnée en colonne stockera les données de la façon suivante (en ... colonne) :
{{< highlight bash >}} Doe:001,003;Smith:002; 001:John;002:Joe;003:Jane; 001:33;002:34;003:32; {{< /highlight >}}
Ceci rend la recherche de valeur par la clé primaire très rapide. Le stockage des données est un équivalent des index sur une base de donnée classique. Cependant cela restreint les critères de recherche. Par défaut, on ne pourra pas faire de requête contenant un "WHERE" sur une colonne n'étant pas une clé primaire. Il faudra au paravant créer un index sur la valeur que l'on veut pouvoir restreindre. On peut le voir sur l'exemple suivant : 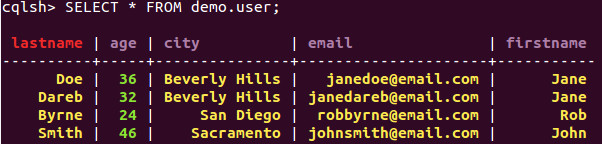
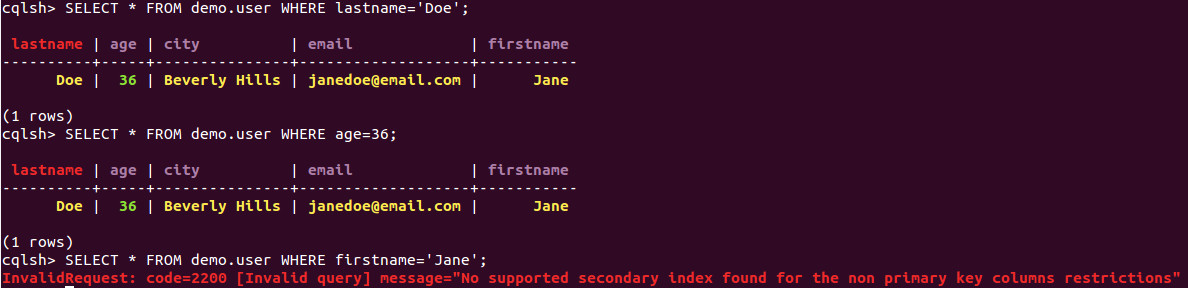 On voit ici que la clé primaire est bien mise en valeur par sa couleur rouge. Il y a un index sur la colonne age, nous sommes donc capables de la requêter. Cependant, sur une requête sur la colonne firstname, nous avons une erreur. Le langage utilisé est similaire au langage que l'on trouve sur les bases SQL classiques. Ce principe de stockage des données est moins performant qu'une base de données classique dans le cas d'un "SELECT * ", car il faudra parcourir toutes les lignes plutôt qu'une. Par contre, elle l'est beaucoup plus dans le cas de recherche d'une valeur particulière.
On voit ici que la clé primaire est bien mise en valeur par sa couleur rouge. Il y a un index sur la colonne age, nous sommes donc capables de la requêter. Cependant, sur une requête sur la colonne firstname, nous avons une erreur. Le langage utilisé est similaire au langage que l'on trouve sur les bases SQL classiques. Ce principe de stockage des données est moins performant qu'une base de données classique dans le cas d'un "SELECT * ", car il faudra parcourir toutes les lignes plutôt qu'une. Par contre, elle l'est beaucoup plus dans le cas de recherche d'une valeur particulière.
Pas de jointures (elles ne sont pas recommandées) :
Du fait de leur structure, les bases de données en colonne n'encouragent pas l'utilisation de jointure. Dans le cas de Cassandra, elle ne le permet que par des outils externes comme Spark, qui effectue l'équivalent du map-reduce des bases Document. L'utilisation d'une base de donnée en Colonne est spécifique à des besoins de performance lors de lectures et d'écritures rapides sur des données précises d'une ligne de donnée. Lors de la lecture d'une ligne entière, ou lors de l'écriture d'une nouvelle ligne, une base de donnée classique sera plus performante. On peut noter que cette structure en colonne peut être copiée sur des bases de données SQL classique. C'est le cas dans certaines sociétés qui utilisent Oracle, et qui ayant eu des problèmes de performance ont modifié la strucutre de leur données. Ce genre de bases ressemblent à une base orientée colonne, mais n'en a pas les performance, sa structure n'étant pas tout à fait adaptée. Les bases de données en Colonne peuvent être utilisées dans des data warehouses pour leur rapidité sur des requêtes complexes sur des valeurs précises. On pourra retrouver des bases de données en Colonne chez les banques, pour un stockages de valeurs boursières, ces valeurs étant très fréquemment modifiées unitairement.
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025



