
KubeCon Barcelone 2019, Day 1 !
Après Copenhague et Seattle, les consultants alter way participent à la KubeCon Europe qui se déroule cette année à Barcelone.
Comme à chaque fois que nous participons à ce genre d'événement, sur OpenStack, AWS ou autre, nous partageons à la fin de chaque journée les éléments marquants de notre journée. C'est parti pour un résumé de notre première journée !
Maintainer Track : Le track des SIGs
Afin de mieux comprendre l'écosystème des contributeurs sur les projets de la CNCF, certains d'entre nous ont axé leur planning sur les conférences ayant un lien avec la communauté. Ces conférences ont un track particulier dans l'agenda, le "Maintainer Track". Voici une présentation de deux d'entre elles, "CNCF CI" et "Azure SIG".
ça y est, notre équipe #AWCC est arrivée à #Barcelone pour la #KubCon de #CloudNativeCon @CloudNativeFdn #cloudcomputing #barcelona pic.twitter.com/2hxdA0BIwA
— alter way (@alterway) 20 mai 2019
Intro: CNCF CI
Ce "Special Interest Group", ou SIG, travaille sur la CI des différents projets CNCF. Le dashboard est disponible sur https://cncf.ci. C'est une sorte de Méta-CI qui teste les projets "graduated" (core) de la CNCF. Il y en a 6 à l'heure actuelle :
- Kubernetes
- CoreDNS
- Envoy
- Fluentd
- Promotheus
- containerd
L'objectif est d'assurer la "cross-compatibilité" des différents projets, et publier l'état des différents dépôts, avec des tests effectués sur des architectures x86 et ARM. Le maintien du dashboard cncf.io revient également à ce SIG.
Les outils utilisés sont Gitlab pour la CI, Terraform et cloud-init pour le déploiement de l'infrastructure, et Helm pour le déploiement et les tests sur les applications.
C'est une équipe d'une petite dizaine de personnes qui gère ce SIG, tous de la même société : Vulk - http://vulk.coop/ On peut considérer que ce SIG est totalement single-vendor. De plus, cette société étant très petite (moins de 10 personnes au total), on peut facilement imaginer ce qui arriverait au projet si cette société venait à disparaître...
Une salle vide sur un sujet pourtant essentiel, la #CI de la #CNCF. On mettra ça sur le dos des donuts sur les stands. #kubecon2019 pic.twitter.com/kUyCJUORPy
— Pierre Freund (@PierreFreund_AW) 21 mai 2019
Être single-vendor n'est pas à mettre à la charge de la société qui a démarré le projet, au contraire. Il est plus qu'honorable de lancer des nouveaux projets, et acceptable que le démarrage ne soit géré que par une société unique. Ce qui serait anormal, c'est que cela le reste... A suivre donc.
SIG Azure
Les SIGs ne sont pas forcément centrés sur des outils, comme la CI, les tests ou la documentation. Ils peuvent également être liés à un fournisseur de service, comme Amazon, Google ou Azure. Nous avons participé à cette session d'introduction du SIG Azure, groupe qui s'intéresse aux sujets de déploiement, maintien et support de Kubernetes sur le cloud de Microsoft, Azure.
Venant de la communauté OpenStack, il est étonnant de voir ce genre de SIG, liés à des sociétés privées. Que les développeurs travaillent pour une société est tout à fait normal, cependant la création d'un groupe lié à une technologie complètement externe au projet peut poser question. Mais ce serait oublier le marché des services managés, en très forte expansion au moins sur la communication, et sûrement sur l'utilisation. La plupart des clouds providers ont leur propre SIG, et contribuent à la fois sur les services mais également sur les projets annexes liés à la compatibilité avec leur propre technologie.
Un des objectifs du SIG, et ils sont nombreux, est d'assurer la compatibilité et le maintien des outils qui permettent à Kubernetes de consommer les ressources Azure, comme les Azure Disk, ou les Azure Load Balancers.
Outre les sujets techniques abordés, il est intéressant de regarder qui participe à ces sessions, et les sociétés qui les organisent. Les deux speakers étaient de Microsoft, bien sûr, et VMware qui à un fort partenariat avec ce dernier. Ce SIG est géré par 4 personnes, "Chairs" et "Tech Leads", dont trois de Microsoft et un de VMware. Rien de surprenant donc. La majorité des personnes présentes dans la session étaient des utilisateurs d'AKS, le service managé d'Azure, ou de Kubernetes sur Azure.
Bajo el hermoso cielo de Barcelona, notre équipe #alterway #Cloudconsulting attend la prochaine conférence au #KubeCon #CloudNativeCon
— Awatif AW (@Awatif__AW) 21 mai 2019
Yo se, en regardant par la fenêtre, vous vous dites : - Pero por qué no estoy en Barcelona? https://t.co/zN3iGB0jOy pic.twitter.com/4ts52muAoq
Breakout Sessions
Build rootless de conteneurs : état de l'art
Aujourd'hui nous allons parler du build de conteneurs rootless. En général, lorsqu'on construit des images avec Docker, les builds sont exécutés avec des droits root sur l'hôte.
The root of all evil : running unnecessary containerized process as root (prerequisite for many attacks).
Lancer des processus en root dans un conteneur augmente également la surface d'attaque lors du build d'image.
Pour parvenir à un build rootless il faut que ces deux conditions soient réunies :
- Pas de processus en ID 0 sur l'hôte
- Pas de root pour les commande RUN dans le namespace de build
Les user namespaces rendent cela possible en partie. Ils permettent de réaliser un remapping entre les utilisateurs du système hôte et ceux du conteneur (guest to host remapping) : le root user dans l'environnement de build est uid 0 privilégié mais mappé à un utilisateur non privilégié sur le système hôte.
En parallèle, shiftfs permet de gérer dynamiquement le remapping des utilisateurs et groupes sur les fichiers.
Pour qu'un build soit reproductible, il faut que celui-ci soit identique (bit à bit), peu importe le système utilisé pour construire l'image. Les spécifications OCI v2 mettent l'accent sur la reproductibilité. Les conditions suivantes doivent être réunies afin d’obtenir une image reproductible au sens strict :
- Dépendances locales ou "pinned"
- Pas d'appel réseau non déterministe
- Artifacts signés
- Produit identique sans comportement lié au temps
Quelles sont les potentielles attaques sur un build ?
- Utilisation malicieuse des FROM (accès aux build secrets depuis une image custom)
- Utilisation malicieuse des RUN (accès aux ports ou services réseaux)
- Docker in Docker : potentiel accès à l'hôte.
Comment se défendre contre de telles attaques ?
- Limiter les accès egress
- Isoler le kernel de l'hôte (par exemple via des technologies comme Kata container ou gVisor)
- Lancer les commandes RUN en tant qu'utilisateur non root dans l'environnement de build.
- Lancer le processus de build en tant qu'utilisateur non root sur l'hôte
- Ne rien partager de non-essentiel
Aujourd'hui, il existe quelques outils qui permettent d'atteindre un certain niveau de sécurité (ou presque...) et qui utilisent chacun des techniques différentes :
- Docker's Buildkit : intégré à Docker v18.06, il peut être exécuté dans Docker et Kubernetes
- Img : utilise Buildkit en backend
- LXC : supporte le mode non privilégié depuis 2013 et est compatible avec les images OCI.
- OpenSUSE's umoci
- Google's Kaniko : supporte Kubernetes, gVisor, Docker, Google Cloud Build)
- Red Hat's Buildah
Kubernetes : failure stories by Zalando
Zalando, important acteur d'e-commerce, nous présente son expérience de Kubernetes en production ainsi que les différents problèmes que la société a pu rencontrer. Commençons par quelques chiffres. Zalando c'est plus de 1000 développeurs, 380 comptes AWS et 118 clusters Kubernetes.
Ils nous présentent ici quelques cas concrets.
1 : Tunnel de paiement.
Problème : Les ALB AWS reportent le compte d'instance healthy à 0. Tous les ingress controllers (skipper) en OOM Killed. Solution : Augmenter les limites de consommation CPU/mémoire des ingress controllers (skipper).
2 : Tunnel de paiement
Problème : Beaucoup d'erreurs 404 dans les logs, l'ingress controller (skipper) surveille l'API server qui était down (OOM Killed). Solution : Augmenter les limites de l'API server.
3: DNS outage
Problème : CoreDNS OOM Killed, dû à une augmentation des requêtes HTTP ce qui a augmenté les QPS sur CoreDNS et donc la mémoire consommée par celui-ci. Solution : Mettre en place du caching DNS avec DNSmasq en plus de CoreDNS.
4 : API latency spikes
Problème : Connexion à etcd timeout par interruption. Problème rencontré uniquement sur les instances de type T2. Solution : Ne plus utiliser les instances de type T2 et ajout de etcd-proxy en tant que sidecar de l'API Server.
5 : Cluster upgrades
Problème : Le déploiement de nouveaux clusters fonctionne from scratch mais pas lors d'un upgrade. Solution : Déploiement d'un cluster dans l'ancienne version puis application des mise à jour et ensuite seulement lancer les tests E2E.
6 : Perte de tous les pods d'un noeuds (OOM Killed)
Problème : Memory leak dans le Kubelet en v1.12.5. Solution : PR upstream.
Si vous souhaitez lire plus de cas concrets, contribuer et/ou racontez vous aussi vos problèmes rencontrés avec Kubernetes, rendez vous sur k8s.af.
GitOps & Best practices for Cloud Native CI/CD, Panel Discussion
- Laura Tacho, Director of Engeenring @ Cloudbees
- Ivan Pedrazas, Solutions Architect @ State Street
- Tracy Miranda, Director of Open Source Community @ Cloudbees
- Alexis Richardson, CEO @ Weaveworks
Format un peu plus inhabituel, cette conférence a pris la forme d'une table ronde avec comme sujet : GitOps et les bonnes pratiques des CI/CD Cloud Native.
GitOps est le nom donné à la pratique de considérer git comme la single source of truth à la fois du code source de votre application mais aussi et surtout de votre infrastructure et de gérer les opérations de cette infrastructure à base de Pull Request. Le concept de Pull Request a été largement popularisé par GitHub et a été repris par ses concurrents (Merge Request chez Gitlab par exemple). Il est néanmoins intéressant de rappeler que les PR n'existent pas nativement dans git. Le nom que l'on donne à ces PR n'a pas d'importance. Il faut simplement y voir une manière de demander une review de sa feature/patch par des membres du projet avec comme objectif le merge du code dans la branche master. GitOps étant une pratique et non pas un outil, utiliser GitHub, Gitlab ou Gerrit n'a aucune importance. Certains sont juste mieux adaptés que d'autres ;)
A quoi ça sert ? Tout d'abord, avec l'utilisation quasi systématique du YAML comme langage de configuration, il devient extrêmement intéressant de stocker ses fichiers texte dans git. Les raisons sont nombreuses et nous les avons déjà longuement abordées dans d'autres articles. Le versionning permet de tracker les changements apportés au code, d'effectuer des releases stables, de revenir en arrière en cas de problème, etc. Les CI modernes ont comme objectifs d'observer un repository git et d'y appliquer une série de tests quand du code est ajouté au repository. Appliquer ces tests à une PR permet de définir rapidement si le code peut être mergé ou non et donc d'intégrer plus rapidement des patchs ou de nouvelles features. Tout cela contribue à améliorer le time to market de façon sereine. Il est important de noter que peu importe la qualité et l'exhaustivité de vos tests, une CI ne pourra jamais vous dire si votre code casse quelque chose, elle ne pourra jamais vous dire si votre feature marche parfaitement comme vous l'attendez. Dans le cas du TDD, elle pourra au moins vous garantir que la feature respecte les tests écrits au préalable.
La sérénité est un deuxième point à considérer. Lorsque le code gérant votre infrastructure se trouve dans git, vous avez la possibilité de casser complètement votre infrastructure (modulo vos clients qui râlent) et de la reconstruire entièrement en vous basant sur votre single source of truth, git. Vous avez bien entendu, grâce au versionnement, il est possible de redéployer une version antérieure ou bien de déployer une release candidate.
Ingress V2 and Multicluster Services
- Rohit Ramkumar, Google
- Bowei Du, Google
Le talk présente l'évolution de la ressource Kubernetes, Ingress. Suite à une enquête réalisée en 2018 auprès des contributeurs, il a été identifié que l'Ingress est perçu comme un outil de Load-balancing niveau L7.
Il existe des différences dans l'implémentation de cette ressource au niveau des cloud providers, cependant une convergence entre les différentes implémentations commence à émerger.
Il faut aussi noter que le concept Service Mesh est récemment apparu, avec un modèle de déploiement différent qui essaye de remplir partiellement le rôle défini par l'Ingress.
Ce talk est principalement une proposition d'une nouvelle implémentation de l'Ingress.
Initialement un Ingress est une ressource utilisée pour définir et configurer différents aspects d'une application frontend tels que les terminaisons TLS et les protocoles L7. Il est représenté au travers d'un modèle d'API. Dans son utilisation, la ressource reste simple et facile à configurer.
Il existe pourtant différents modèles d'API implémentés :
- L'objet Gateway chez Istio
- L'objet IngressRoute chez Contour
Cette disparité rend difficile l'intégration de nouvelles fonctionnalités et limite la portabilité des applications entre différents environnements pour l'utilisateur final.
La proposition faite au travers de ce talk est une nouvelle implémentation de l'objet Ingress (actuellement en Beta 1) introduisant de nouveaux concepts comme :
- le Gateway (inspiré de Istio)
- le GatewayClass
- le VirtualHost
Cette nouvelle implémentation implique aussi une réorganisation de l'API représentant l'Ingress. Cette réorganisation consiste à avoir 2 types d'API :
- une API core, supportée à 100% par tous les cloud providers, et aux autres ingress controllers, facilement portable
- une API extensible permettant de rajouter différentes fonctionnalités.
Le talk continue ensuite d'explorer les différentes possibilités qu'offre cette nouvelle implémentation :
- des services déployés sur plusieurs clusters ayant des locations géographiques différentes
- la réduction de la latence entre des applications situées dans la même région géographique
- une approche cloud hybride de l'infrastructure
Alors que tout le monde est parti à l'apéro pour les 5 ans de Kubernetes, l'équipe @alterway paufine son article de blog.
— Pierre Freund (@PierreFreund_AW) 21 mai 2019
📢 Rendez-vous sur https://t.co/SZkS7hdueu pour le résumé de la première journée !#KubeCon #kubecon2019 #Kubernetes pic.twitter.com/DRZ2sImhfK
Bulletproof Kubernetes - Learn by Hacking !
Connaissez-vous les points de vulnérabilité de votre infrastructure Kubernetes ?
L'évolution rapide des outils Cloud Native peut mener à l'oubli des recommandations de sécurité les plus basiques. Petite piqûre de rappel lors de cette présentation approfondie où Ana Calin ((Paybase)) et Luke Bond ((Control-plane)) nous ont préparés un exercice de pentesting sous la forme d'un CTF. Avant de nous laisser la main, les orateurs nous ont remis en tête les vulnérabilités classiques d'un cluster et les bonnes pratiques à suivre pour éviter une catastrophe.
Dans un écosystème de containers, il y a plusieurs questions à se poser en fonction du niveau où l'on se place dans un environnement :
-
Est-ce que notre infrastructure est suffisamment sûre pour déployer des conteneurs ? (Infrastructure security)
-
Est-ce que l'image que nous souhaitons utiliser est sûre pour le build et le déploiement ? (Software supply chain security)
-
Est-ce que l'exécution du conteneur est sûre ? (Container runtime security)
Cette logique s'applique évidemment à Kubernetes. La surface d'attaque d'un cluster peut être large et chaque strate de l'architecture peut potentiellement mener à une élévation de privilèges :
- Un conteneur non sécurisé peut donner à un attaquant la possibilité de s'échapper et de prendre le contrôle du noeud sous-jacent
- Les noeuds permettent de contrôler les pods et potentiellement de remonter jusqu'aux masters
- Les masters peuvent donner à un attaquant le contrôle entier du cluster
- Un service etcd vulnérable peut également donner accès à l'administration complète du cluster (accès, modification, destruction)
Les points de vulnérabilité se trouvent généralement au niveau des applicatifs qui tournent sur le cluster (code source ou configuration de l'application) mais pas seulement ! Des erreurs dans la configuration de Kubernetes sont possibles, par exemple lors de l'écriture des manifests, de leur déploiement ou dans les phases opérationnelles.
Une fois dans le cluster, un attaquant dispose d'un panel d'outils pour pivoter :
- Des exploits au niveau du Kernel (Dirtycow ou autres 0days)
- Des exploits au niveau de la container runtime (par exemple la CVE-2016-9962 touchant runc et permettant une élévation de privilèges)
- L'utilisation de mauvaises configurations de l'orchestrateur (namespaces partagés, non-implémentation des user namespaces pour les ressources partagées, montage du volume de l'hôte dans un container, pods non sécurisés, containers avec privilèges, etc.)
- L'exploitation du réseau (sniffing, brute forcing des pods adjacents ou services kubernetes, attaque des certificats ou de leur algorithme...)
- L'exploitation des applications, de leurs secrets ou de leurs roles.
Tous ces exemples de vulnérabilités et de risques potentiels nous montrent l'importance du suivi des bonnes pratiques de sécurité, tout au long du cycle de vie du cluster et dès son déploiement initial.
La slide suivante présente des recommandations pour le maintien d'une bonne hygiène de sécurité, sur la prévention des attaques connues et sur la limitation de l'impact des microservices qui pourraient devenir/être compromis.
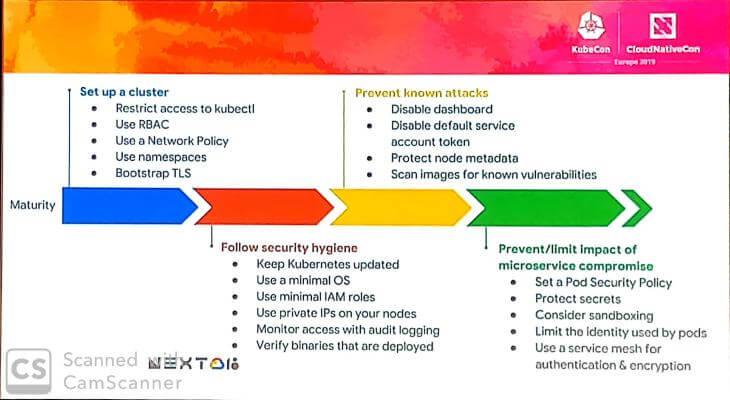
Maintenant que vous avez toutes ces clés en main, si vous souhaitez vous exercer chez vous, retrouvez le CTF sur GitHub: calinah/learn-by-hacking-kccn
A demain pour le résumé de la deuxième journée, si nous survivons à la soirée "Kubernetes or Die", organisée par Mirantis.
Just 1 day until the mega #K8sorDie party and we are SO stoked! Have you RSVPd yet? You do not want to miss this one. #CloudNativeCon #KubeCon #Kubernetes https://t.co/MbiDJcTDkl pic.twitter.com/hbWJMkNtUy
— Mirantis (@MirantisIT) 20 mai 2019
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025



