
Sommaire de ce dossier complet KubeCon + CloudNativeCon 2018 à Copenhague par Osones :
C'est la troisième et dernière journée à Copenhague pour la Kubecon 2018 ! Le schéma reste le même : une keynote, des conférences, et une bonne session de blogging :) Comme dans toutes les conférences qui durent un peu, la fatigue s'est légèrement faite sentir - la soirée officielle de la CNCF avait lieu la veille à Tivoli, parc d'attractions historique de Copenhague, dont nous parlons en fin d'article.
Néanmoins, la conception du Bella Center, la qualité de la nourriture et la taille relativement réduite de la conférence facilitent notre acclimatation. En parlant de chiffres, et en comparant des pommes et des oranges, cette édition de la Kubecon rassemble 4 200 participants contre plus de 40 000 lors du dernier AWS Re:Invent, et 5 000 lors du dernier OpenStack Summit US à Boston.
Assez parlé, voyons sans plus attendre ce que nous avons retenu de la troisième et dernière Keynote de cette Kubecon 2018 !
La troisième Keynote
Le premier talk de cette dernière Keynote est présenté par David Aronchick (Product Manager, Cloud AI et co-fondateur de Kubeflow, Google) et Vishnu Kannan (Sr. Software Engineer, Google), qui nous ont présenté Kubeflow. Kubeflow est une stack de Machine Learning (ou ML) compilable, portable et évolutive, conçue pour Kubernetes. Cette intégration à Kubernetes se traduit notamment par :
- des déploiements faciles, répétables et portables sur des infrastructures diverses (cluster de production / cluster de formation / ordinateur portable)
- la possibilité de déployer et de gérer des microservices "faiblement couplés" pour paralléliser les tâches
- la scalabilité à la demande pour vos stacks de ML
Parce que les praticiens du ML utilisent un ensemble d'outils divers, l'un des objectifs clés est de personnaliser la stack en fonction des besoins des utilisateurs (dans des limites raisonnables) et de laisser le système s'occuper de la mise à disposition des outils dont ils ont besoin pour se concentrer sur leur travail.
C'est en fin de compte un ensemble de manifestes simples qui vous donnent une stack ML facile à utiliser sur Kubernetes, et qui peuvent se configurer automatiquement en fonction du cluster dans lequel il est déployé.
Du côté des retours utilisateur, Sahil Dua (Software Developer, Booking.com) a présenté leur déploiements de modèles de deep learning en production (utiles entre autres pour optimiser leur campagne de pub et pour le tagging des photos), la manière dont ils ont choisi leurs outils et développé leur infrastructure interne de deep learning en utilisant Kubernetes. Il a évoqué la manière dont les modèles sont entraînés dans des conteneurs Docker, l’entraînement TensorFlow distribué dans un groupe de conteneurs, le recyclage automatisé des modèles et enfin, le déploiement de modèles pour servir les prévisions.
Nous avons enfin eu la chance d'assister à un talk qui a étonné par sa pertinence et sa fraîcheur, car non "technique" et plutôt transversal : comment comprendre et s'inscrire dans un environnement concurrentiel en perpétuelle évolution. Et bien ça fait du bien de pouvoir prendre de la hauteur en Keynote plutôt que de se taper les slides commerciales des sponsors ! Simon Wardley, Researcher for Leading Edge Forum, est un consultant connu dans le milieu, ayant notamment contribué à l'installation d'Ubuntu comme un acteur majeur du Cloud Computing. La problématique : cartographier le marché pour en comprendre les dynamiques et anticiper les prochaines tendances : ici, le serverless. Pour ceux qui ont le temps et l'envie de lire le contenu de ce talk en détails, je ne peux que vous renvoyer vers l'article de Wardley lui-même "Why the fuss about Serverless" (EN, linkedin), et ses articles sur Medium concernant sa méthode de cartographie. Nous vous notifierons d'un petit Tweet (@osones) dès que la vidéo sera disponible sur Youtube.
Retours de quelques unes des conférences
The Serverless and Event-Driven Future - Austen Collins, Serverless
Derrière le buzz du serverless se cache une complexité qui entrave son adoption. On a aujourd'hui des plateformes FaaS (Function as a Service) chez pratiquement tous les acteurs du cloud public, après l'ouverture de ce marché par AWS en 2014 avec Amazon Lambda. Les efforts open-source, dont Kubeless et Openwhisk, sont nombreux. Austen Collins, fondateur de Serverless Inc., profite de cette session pour nous rappeler que sa société travaille pour la simplification et l'harmonisation de ce type de service. Il prévoie une croissance importante du serverless, car des "events" deviennent omniprésents : IOT, capteurs en tout genre, etc.
Le principal obstacle à l'interopérabilité des FaaS est que ces "events" sont émis dans un format incompatible entre les différents fournisseurs et, qu'un même fournisseur pouvait même proposer différents formats. La CNCF veut prendre un rôle d'arbitre dans ce désordre en standardisant l'enveloppe des events dans une spécification grâce à son projet CloudEvents. Cela devrait faciliter la portabilité du code, mais aussi une intégration plus forte entre les différents clouds et, in fine, une adoption plus rapide de ce paradigme de développement.
Pour le moment, Azure a été le premier cloud public à annoncer un support natif de CloudEvents dans son event grid.
La session s'est achevée avec une démo aussi sympathique qu’impressionnante, où Collins a posé une photo dans S3 qui a ensuite déclenché des exécutions de code dans 11 clouds différents en parallèle. L'image a été analysée dans les clouds qui comportent ce type de service. Et pour l'anecdote, c'est AWS Rekognition qui s'en est le mieux sorti, parmi beaucoup de fails dont certains assez drôles. Le speaker a fini par mentionner le service Hosted Event Gateway que sa société a lancé en beta, et qui est open-source. Un projet à suivre de près !
Kubectl Plugins 101 - Jonathan Berkhahn, IBM & Carolyn Van Slyck, Microsoft
Jonathan Berkhahn (IBM) et Carolyn Van Slyck (Microsoft) nous présentent l'architecture plugins de Kubernetes qui est en alpha en ce moment. Cet effort est né du projet svcat, actuellement disponible en standalone binary ou sous forme de plugin kubectl. Leur aspiration est de s'intégrer pleinement dans kubectl et c'est pour cette raison qu'ils ont gardé une interface très similaire et ont évité d'implémenter des fonctionnalités déjà présentes dans kubectl.
Un plugin consiste en un fichier plugin.yaml et d'un exécutable optionnel. Ces fichiers se trouvent dans ~/.kube/plugins et leur complexité peut aller du simple appel bash à un CLI complet comme svcat, projet libéré par Van Slyck. Le fichier plugins.yaml peut devenir très long et compliqué à entretenir, mais un générateur est fourni dans le projet svcat et son utilisation est fortement conseillée. Pour ceux qui se lancent dans l'aventure, Berkhahn recommande de se servir de son logiciel pluginutils, qui évite d'écrire une bonne partie du boilerplate nécessaire.
Pour finir ce talk, quelques conseils pour les futurs développeurs de plugins : évitez d'accepter des flags dans vos plugins qui seraient en collision avec des flags kubectl (ça ne marchera pas, et vous n'aurez aucune erreur ni avertissement), ne nommez pas vos plugins comme des verbes kubectl existants (par exemple, évitez de développer un plugin appelé "logs"). Le keyword "plugin" risque de disparaître, et le verbe kubectl tournera alors en détriment de votre plugin. Van Slyck donne quelques idées de plugins qu'on pourrait développer, comme un plugin qui enregistrerait des commandes kubectl précédemment envoyées afin de pouvoir les rejouer automatiquement.
Introducing Amazon EKS - Brandon Chavis & Arun Gupta, AWS
La première annonce a été faite au dernier Re:Invent à Las Vegas, à laquelle Osones a assisté. Cette annonce date donc de Novembre 2017, et même la Preview est encore en attente pour beaucoup de monde (dont nous), cette conférence était donc très attendue et beaucoup de réponses étaient attendues par les intervenants.
La peur d'avoir une présentation purement commerciale était présente, mais nous avons été ravis d'avoir plus de détails techniques jusque là pas présentés, et des réponses à un bon nombre de questions (dont une des nôtres).
La première partie présente généralement les intérêts d'avoir poussé ce Amazon Elastic Container Service for Kubernetes (EKS), en bref :
- Supporter des workload de production
- Fournir une expérience identique à celle d'un cluster Kubernetes déployé depuis les sources upstream
- Intégrer d'éventuels services AWS pour éviter toute migration trop lourde (notamment IAM, CloudTrail, CloudWatch)
- Contribuer upstream à Kubernetes
Ensuite on rentre dans les détails un peu plus techniques, notamment le fonctionnement du service "behind the scenes".
Provisioning du Control Plane
La création du cluster (Control Plane) se fait par un simple aws eks create-cluster --cluster-name <nom-du-cluster> .... Suite à cette commande, AWS génère tout un control plane, à savoir :
- 3 Masters Kubernetes répartis sur 3 zones de disponibilité
- 3 Etcd répartis sur 3 zones de disponibilité
- Des Security Groups afin d'accéder à l'API Kubernetes
- Un role pour que Kubernetes puisse générer des ressources
- Un Endpoint pour contacter l'API
On remarquera que les serveurs Etcd et les masters Kubernetes sont séparés. Un point de sécurité en plus, les serveurs Etcd sont complètement chiffrés.</ br>
Ces ressources sont créées derrière un NLB avec des IP statiques, afin d'éviter tout problème de certificat. L'endpoint qui sera retourné pointera donc vers ce NLB, afin de contacter l'API Kubernetes. La version de Kubernetes installé sera la dernière version stable, actuellement la version 1.9 en preview, afin d'éviter toute faille majeure ou autre souci du genre. La version de Kubernetes est purement celle récupérable upstream, et les features supplémentaires déplyées sur EKS seront des contributions upstream par l'équipe EKS.
Parmis ces intégrations, notons l'effort sur l'authentification qui se fait via le service IAM, comme décrit sur le schéma suivant :
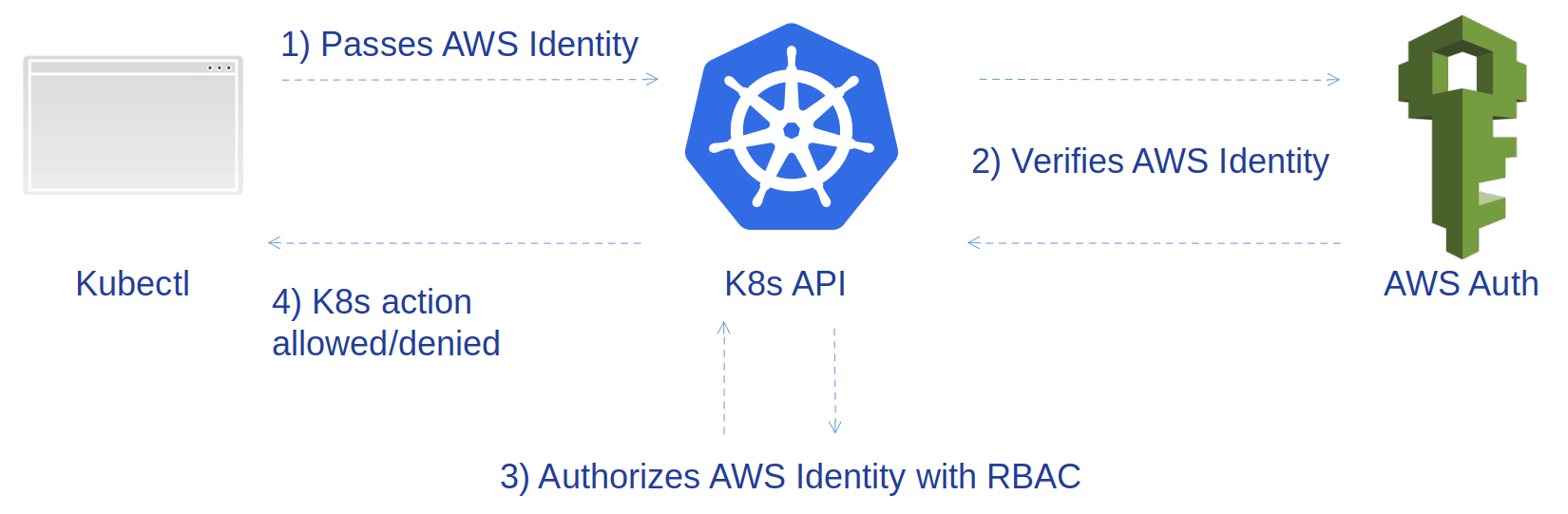
C'est une contribution disponible dans la version 1.10 de Kubernetes.
Provisioning des workers
Du côté des workers, c'est assez similaire à ECS, c'est à dire qu'il sont gérés par nous, via des AMI. Les instances vont s'enregistrer dans le cluster créé auparavant. Pour le choix des AMI, il existe 2 solutions :
- L'AMI qui dont le code sera OpenSourcé (construite avec Packer) le jour de l'ouverture officielle du service
- Une AMI faite via Packer à partir du code source de l'image officielle d'AWS EKS
On salue l'effort d'AWS de ce côté, qui nous ouvre la possibilité d'utiliser un OS qui nous va mieux, par exemple CoreOS, si toutefois ceci reste possible, nous le saurons le jour de la sortie officielle.
Le dernier point à noter et l'intégration de EKS avec les VPC via CNI. Ainsi tous les pods pourront avoir une addresse IP piochée dans le pool d'IP du VPC. A noter toutefois les limitations quant à cette utilisation des ENI (Elastic Network Interface), qui limite le nombre d'interfaces réseau selon le type d'instance. Mais des tests sont nécessaires pour affirmer que l'on pourra atteindre ces limites, car le nombre d'interfaces réseau augmente rapidement avec le type d'instance utilisé.
Séance Q&A
De nombreuses questions ont été posées sur la date de sortie, où les intervenants AWS sont restés stoïques, sur une sortie "during 2018". Nous avons une question qui nous intéressait particulièrement, concernant l'Open Service Broker (OSB). En effet nous avons eu une présentations par Azure sur un déploiement de ressources managées depuis Kubernetes, qui sont donc vues comme un service Kubernetes, avec laquelle les autres services peuvent intéragir facilement (notamment via les secrets Kubernetes). La question fut sur la disponibilité de ce Borker pour AWS. On nous a répondu qu'un article parlait de cette implémentation pour les services d'AWS existait, et que les services S3, SQS et RDS était déjà disponibles, nous allons donc travailler là dessus, et qui sait, vous écrire un article sur le Service-Catalog et l'OSB :)
Références :
Secure Pods
Tim Allclair, Software engineer @ Google
Un pod sécurisé (ou pod sandboxé) est un concept pouvant être obtenu de multiples façons.
La première ligne de sécurité est constituée des éléments habituels :
- Firewall
- Check d'intégrité
- IDS
- IPS
- WAF
Néanmoins, ces éléments protégeant un système - plus ou moins - efficacement contre les attaques extérieures se retrouvent démunis face à des attaques intérieures.
Premier problème, le code applicatif. La confiance ne doit jamais être accordée à du code et celui ci doit être considéré comme un élément extérieur. Un pod touché par une faille ne doit pas constituer une menace pour les autres pods ou le reste de l'infrastructure.
Principale surface d'attaque "intérieure" : le kernel. L'évasion d'un container est la première peur de l'administrateur. Contrairement à des machines virtuelles, le kernel est partagé entre les containers et l'exploitation d'une vulnérabilité kernel (ou d'un de ses modules) peut potentiellement permettre l'évasion de tous les pods d'un host. Plusieurs outils de sécurité peuvent renforcer la sécurité d'un pod Kubernetes :
- seccomp qui provient de Docker fourni un profil par défaut relativement intéressants (désactivé par défaut dans Kubernetes)
- apparmor
- selinux
securityContext: RunAsNonRootet spécifier un user pour le run (non root)
Deux technos déjà présentés sur ce blog proposent d'autres solutions :
Parmi les problèmes engendrés par l'utilisation de ces moyens, on retrouve une baisse des performances ainsi qu'une compatibilité imparfaite avec le reste de Kubernetes, l'intéraction avec les namespaces n'est pas forcement possible avec toutes les solutions.
Dans la liste des autres surfaces d'attaques notables, Tim Allclair évoque aussi :
- le stockage. La CVE-2017-1002101 constitue l'exemple parfait d'élévation de privilège en tirant profit du stockage, du mécanisme de liens symboliques et de points de montages inhérents à Docker (aujourd'hui corrigé).
- les services (logging, monitoring...), notamment via l'exploitation de vulnérabilités liées aux agrégateurs de logs ou autres outils de supervision
- le réseau, vecteur d'exfiltration d'identifiants, de métadonnée notamment via des ports sans authentification
- le matériel, spectre et meltdown nous rappelant à quel point il est difficile de se protéger des exploitations de vulnérabilités hardware.
Parmi les outils de prévention et de protection contre ces vulnérabilités, les sandbox sont évoquées à plusieurs reprises pendant le talk. C'est une évolution très attendue, qui devrait arriver en alpha avec Kubernetes 1.12 et qui permettra de renforcer considérablement l'isolation des pods au prix d'une baisse de performance (overhead mémoire qui peut malheureusement être non négligeable) et d'un risque d'incompatibilité. Une réponse très expérimentale pour le moment donc, qui ne résoudra par tout.
Si nous devions retenir une bonne pratique à suivre de cette conférence, il s'agirait probablement de leur politique de "Two security boundaries before data`, un principe que Google suit pour assurer l'existence de deux barrières
A Hackers Guide to Kubernetes and the Cloud
Rory McCune, Managing Consultant, NCC Group PLC
Rory McCune commence par faire un constat simple, les attaques de cluster Kubernetes augmentent. Comment protéger un cluster Kubernetes ?
Rory conseille dans un premier temps de définir un modèle de menace ("Threat model") afin d'énumérer les types d'attaque auxquelles on peut être exposé. L'attaque peut être aléatoire ou ciblée : * Si aléatoire, alors le but de l'attaquant peut simplement être de trouver une faille dans le système afin de miner de la crypto-monnaie sur votre infrastructure par exemple * Ciblée, par exemple si vous êtes une banque
Quelles sont les attaques possibles sur cluster ?
- Le serveur d'API
- L'Etcd
- Le Kubelet
- Le cloud provider (en récupérant les accès au compte par exemple)
Pour ne citer que l'exemple d'etcd, Rory nous montre que plus de 1800 clusters Etcd ne sont pas sécurisés via une simple recherche depuis Shodan.
Comment faire ?
- La directive Insecure Port doit toujours être désactivée.
- Contrôler l'accès au Kubelet : anonymous-auth = false, désactiver le port read only.
- Contrôler l'accès à l'etcd :
client-cert-auth= true - Restreindre les privilèges des conteneurs
- Utiliser les RBAC pour sécuriser les accès
- Bien définir les NetworkPolicy pour l'isolation des namespaces/pods
- Faire des upgrades régulières
TL;DR NIST Container Security Standards
Elsie Phillips, Product Marketer, CoreOS
Le NIST, National Institute of Standards and Technology, a sorti une publication donnant une liste des risques inhérents aux conteneurs ainsi que des recommandations pour contrer ces risques.
Dans cette présentation, Elsie a tenté de résumer les 63 (!) pages du documents. Bien qu’impressionnant, il est en réalité très bien structuré :
- 6 pages listent les risques associés aux conteneurs ;
- 12 pages donnent des recommandations.
Le reste du document étaye les arguments exposés et les solutions proposées notamment au travers des 23 pages d'annexes... Si ces quelques lignes vous ont donné l'envie de le lire, vous pouvez le retrouver ici.
Tivoli Gardens Party
Clôturons ce récit de trois jours intenses par une note plus légère: la grande soirée de cette KubeCon 2018. Car oui, c'est aussi important d'avoir de beaux événements pour la communauté ! Pour l'occasion la CNCF nous a ouvert les portes de Tivoli Gardens, un parc d'attractions en plein cœur de Copenhague. Ouvert en 1853, Tivoli Gardens est le deuxième plus ancien parc d'attraction du Danemark. Attirant 4 millions de personnes chaque année. Auto tamponeuse, roller coaster, "Golden Tower" pour les plus courageux (une tour qui vous élève à plus 60 mètres avant de vous lâcher en "chute libre")... Toutes les attractions étaient disponibles gratuitement pour les heureux détenteurs du bracelet KubeCon. C'était donc l'occasion de networker autour d'une bière, des buffets, ou de sucreries géantes gagnées à des jeux de hasard - avec modération bien entendu.
La team Osones
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025



