
Après Paris et Barcelone, l'OpenStack Summit revient sur le Vieux Continent et pose ses valises dans la capitale allemande !
Comme toujours, alter way Cloud Consulting vous propose un retour sur les faits les plus marquants de ce 18ème summit OpenStack !

Keynotes
Second Summit de 2018, nous sommes donc de retour en Europe. C'était clairement déjà dans l'air du temps lors des derniers événements, mais nous passons à Berlin à la vitesse supérieure sur le thème de l'Open Infrastructure. Le concept est mis en avant par la Fondation OpenStack pour illustrer son positionnement de plus en plus global et de moins en moins OpenStack-centré.
OpenStack reste la base de l'Open Infrastructure martèle Jonathan Bryce, Directeur Exécutif de la Fondation. Au travers de nouveaux projets, non-OpenStack mais sous la tutelle de la Fondation OpenStack, ainsi que par les interactions qu'OpenStack développe avec nombre d'autres projets d'infrastructure open source - à commencer par Kubernetes -, la Fondation vise à placer OpenStack dans un écosystème plus large.
C'est dans ce cadre que les prochains Summits, à commencer par celui de Denver au premier semestre 2019, s’appelleront dorénavant Open Infrastructure Summit.
Parmi les autres sujets abordés lors de ces keynotes matinales : un cas d'utilisateur inattendu, et le cloud public OVH.
Joerg Gross et Georg Stausberg sont les orateurs qui ont présenté le rôle fondamental joué par OpenStack dans le système de gestion d'une usine textile. Ou comment OpenStack joue indirectement un rôle encore plus important qu'on ne pouvait l'imaginer dans notre vie quotidienne !
Enfin, OVH a partagé un certain nombre de chiffres significatifs en ce qui concerne leur cloud public : nombre de datacenters, nombre d'instances en fonctionnement, ou encore le nombre de création d'instances.
Interesting number from @OVH, more than the number of running instances, it shows how cloudy the workloads are #OpenStackSummit pic.twitter.com/sw0lKDK8fo
— Adrien Cunin (@Adri2000_OS) 13 novembre 2018
Les vidéos des keynotes, ainsi que celles de nombre de sessions évoquées ci-dessous, commencent à être disponibles en ligne https://www.openstack.org/videos/summits/berlin-2018, alors n'hésitez pas !
Breakout sessions
Kuryr: project update and roadmap
Kurry est un plugin réseau pour Kubernetes permettant de fournir aux PODs un accès natif aux réseaux OpenStack, c'est-à-dire sans overlay et sur la même plage IP.
À la base, Kuryr était également compatible avec Docker. À partir de Rocky, kuryr et kuryr-libnetwork restent toujours maintenus mais ne sont plus développés activement.
Les projets suivants (liés à l’intégration avec Cinder qui est maintenant native à Kubernetes) seront dépréciés dans Stein :
- fuxi
- fuxi-kubernetes
- fuxi-golang
Le développement sera concentré sur :
- kuryr-kubernetes, qui permet de fournir le réseau Neutron aux PODs
- L’intégration des services Kubernetes avec Octavia et Neutron-LBaaS
- Les tests tempest de Kuryr Kubernetes
Kuryr pouvait précédemment fonctionner sans CNI (Container Network Interface), cette fonctionnalité est maintenant dépréciée et kuryr-daemon (intégration avec CNI) est maintenant obligatoire.
Pour le moment (Rocky), Kuryr est compatible avec Kubernetes <= v1.10, Stein supportera Kubernetes jusqu’à la v.1.12 (qui est la dernière version stable à ce jour)
Dans les nouveautés de Rocky, on notera principalement:
- L'ajout de la haute disponibilité (actif/passif) pour kuryr-controller (composant fonctionnant sur Kubernetes) se basant sur les bonnes pratiques Kubernetes
- Le support des healthchecks Kubernetes pour kuryr-controller
- Implémentation des règles d'Ingress (au sens objet API) par Octavia L7
- Le support de multiples cartes réseau par POD
- Support basique du multi-tenancy au niveau réseau / namespace Kubernetes
- La possibilité de choisir plus granulairement les ressources gérées par Kuryr
Pour revenir sur le dernier point, certaines ressources se chevauchent entre Kubernetes et Kuryr, il est maintenant possible de choisir quelle ressources seront gérées par Kuryr :
| Handler | Kubernetes resource |
|---|---|
| vif | Pod |
| lb | Endpoint |
| lbaasspec | Service |
| ocproute | Route |
| namespace | Namespace |
Le cas d'utilisation le plus fréquent est le choix entre kube-proxy ou neutron-lbaas pour l’implémentation des services (au sens objet API) Kubernetes.
En ce qui concerne la roadmap pour les futures releases (Stein, Train...), on distingue :
- Le support des NetworkPolicy Kubernetes
- DPDK
- SR-IOV
- Le support des services UDP (via Octavia)
Pour aller plus loin, retrouvez les slides complètes ici
Advanced Networking Services: Load-Balancing as a Service (LBaaS) / Octavia project onboarding
Présentées respectivement par AVI Networks et RedHat.
Ces deux conférences, l'une proposée par un utilisateur et l'autre par l'équipe projet, ont eu pour but de présenter le Load-Balancing as a Service, connu aussi sous le nom d'Octavia.
Tout d'abord, à quoi sert un load-balancer : le but de ce service est d’assurer une haute disponibilité et performance, c'est à dire d’être toujours capable de proposer le service promis, même en cas de panne sous-jacente.
Dans la liste des fonctionnalités que l'on attend de la part d'un load-balancer, on retrouve :
- La persistance des sessions : affinité à un backend spécifique pour éviter les rejeux d'authentification par exemple, essentiel pour les applications stateful
- Routage sur la base de critères avancés : possibilité de gérer l'affinité d'une session à un backend spécifique en fonction de l'IP source, de la géolocalisation, etc., et persistance de ce choix
- La capacité d'agir en tant que terminaison SSL
- Le rate limiting, notamment pour éviter la saturation des backend et toute forme de denial of service
- L'authentification (notamment dans des cas d'usage en SSO)
- La tolérance à la panne d'un backend.
Pour la haute disponibilité du service de loadbalancing lui-même, il existe deux types de configuration : active-active, configuration pour laquelle chacun des nœuds est sollicité et en cas de panne de l’un des nœuds le service reste assuré par les autres encore en place, active-standby, où les nœuds non utilisés sont prêts à prendre le relai en cas de panne. Dans les deux modes, le load-balancing propose généralement une seule IP à l’extérieur et va communiquer avec le serveur disponible afin de rendre le service demandé via un mécanisme de VIP ou d'annonce de routes.
Revenons à OpenStack. Octavia apparaît comme un projet à part entière avec la release Ocata. Avant, le service LBaaS était un plugin de Neutron comme le FWaaS par exemple. Cette évolution a été effectuée en deux étapes :
- Octavia V1 : Neutron redirige les instructions LBaaS vers un service Octavia.
- Octavia V2 : Nouveau endpoint LBaaS tenu par Octavia. Neutron n'est plus dans la boucle et Octavia devient un projet indépendant.
Attention ne pas mélanger avec les version de l'API LBaaS. L'API LBaaS est l'ensemble des instructions possibles pour manipuler les loadbalancers. Il existe 4 versions:
- Neutron LBaaS V1 (DEPRECATED), introduit dans la version Grizzly et deprecated depuis Liberty
- Nentron LBaaS V2 (DEPRECATED)
- Octavia LBaaS V1 (DEPRECATED), c'est l'API interne d'Octavia V1, située entre Neutron (qui expose l'API Neutron LBaaS V2 en externe) et Octavia
- Octavia LBaaS V2
Les limitations de LBaaS v1.0 étaient de ne pas proposer plus d’une IP virtuelle (VIP) ainsi que de ne pas proposer de terminaison SSL. LBaaS v2.0 quant à lui ajoute une couche de « listener » auxquels il est possible d’associer l’identifiant TLS (SNI), les secrets (qui peuvent ensuite être gérés par Barbican par exemple) ainsi que la possibilité de mettre en place des politiques de load-balancing. Cependant tous les protocoles ne sont pas supportés (pas d'UDP, terminaisons SSL HTTP uniquement), la réencapsulation pour un backend SSL est impossible et il n’est possible que d’avoir un seul certificat. Octavia vient régler ces problèmes et ajoute par ailleurs des fonctionnalités de recueil de statistiques pour les listeners, la mise en place de quotas par exemple et plus de possibilités de surveillance des services de backend.
Plus précisément, voici l’architecture d’Octavia :
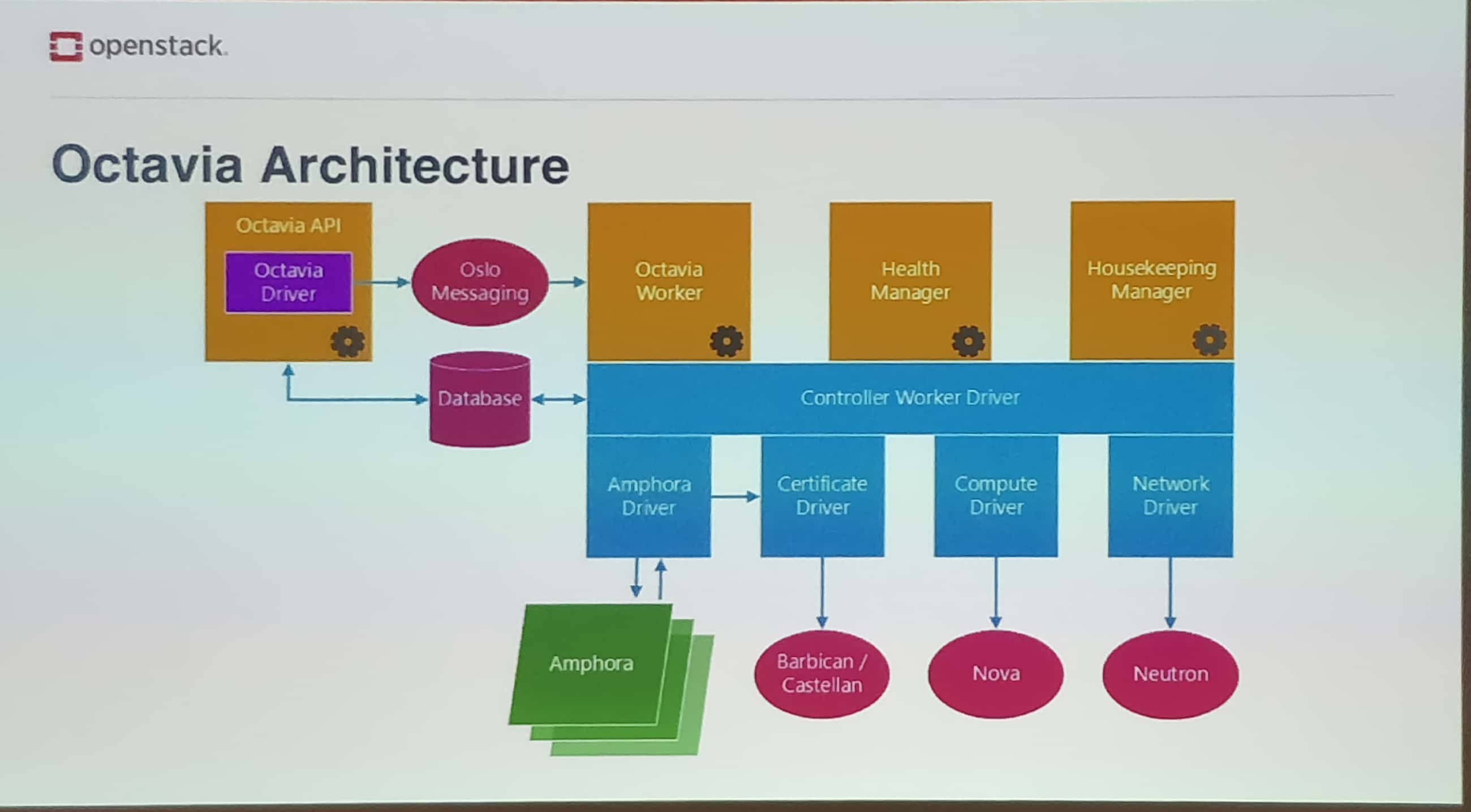
"Ocado Technology's robotic warehouses and grocery delivery: using OpenStack" présenté par Ocado
Ocado est une solution de e-commerce et de logistique qui gère en particuliers des biens consommables avec des besoins de conditionnement très différents. Par exemple, dans leurs entrepôts, Ocado doit gérer des problématiques de chaîne du froid pour des surgelés ou encore de fragilité pour les produits délicats tels que les fruits, etc. Le but d'Ocado est donc de mettre en place des entrepôts entièrement automatisés, n'ayant besoin d'aucune intervention humaine et respectant les différentes contraintes imposées par les produits traités ainsi que par les consommateurs.
Les problématiques à traiter sont les suivantes :
- comment, en partant de rien, est-il possible de mettre en place de tels entrepôts ?
- comment s'affranchir de la condition du nombre et être capable de redéployer le même environnement peu importe la dimension demandée ?
- comment gérer la quantité de données remontées par les robots gérant cet entrepôt ?
Une réponse aux premières problématiques est la mise en place d'une solution modulaire et l'utilisation de micro-services, ce qui va faciliter le passage à l'échelle.
Pour répondre à la dernière problématique, une mise en contexte supplémentaire pourrait-être intéressante. Les entrepôts gérés sont de dimensions telles que les déplacements à l'intérieurs de ceux-ci se font uniquement en voiture et si l'on se place d'un côté de l'entrepôt, il est quasiment impossible de voir l'autre bout. En terme de nombres :
- 250 000 emplacements différents
- Plus de 3 millions de routes calculées par seconde
- Récupération et ensachage des ordres de consommateurs en moins de 5 minutes
- Robots se déplaçant de 4m/s, avec des distances de sécurités de 4mm. Ces données laissent imaginer l'ampleur des contraintes de latence pour le traitement des données de pilotage des robots !
Toutes ces données sont récupérées et traitées par un OpenStack déployé grâce à Puppet et avec une gestion automatique supplémentaire du hardware. Ocado a aussi mis en place un protocole 4G qui permet de récupérer toutes ces données avec une latence très faible.
Ocado utilise comme Netflix Chaos Monkey pour valider la résilience de l'infrastructure OpenStack deployé, en désactivant au hasard des nœuds de production à des moments totalement aléatoires.
Ironic : Project Update
Ironic est le service de BareMetal au sein du projet OpenStack. Ce projet a débuté comme un plugin pour Nova et est progressivement devenu un projet à part entière. Nova vise à créer des machines virtuelles tandis que Ironic vise à provisionner des serveurs physiques. Il utilise par défaut le protocole IPMI et PXE pour provisionner ces serveurs. Un des points remarquables de Ironic est qu'il peut être utilisé en standalone sans dépendre des autres projets OpenStack (excepté Keystone évidemment).
Cette session était l'occasion de faire un point sur l'état de Ironic et sur les futures évolutions à venir pour les releases Stein et Train.
Le premier point à prendre en compte concerne l'adoption de Ironic, en un an, le nombre de cloud OpenStack disposant d'Ironic en production est passé de 19 à 23%. Cette augmentation est notamment due à l'intérêt qu'apporte Ironic dans le déploiement de clusters Kubernetes. En effet, en terme de performance, il est intéressant de faire travailler Kubernetes directement sur des machines physiques pour éviter une couche d'abstraction supplémentaire.
Autre chiffre en augmentation, le pourcentage de contributions venant des opérateurs et non des développeurs. Alors que celui-ci restait proche des 3-4% dans les précédentes releases, il a atteint 10% avec Rocky. Ceci est un vrai signe fort d'adoption et de maturité.
Et enfin, voici la liste des fonctionnalités qui devraient être introduites dans la release Stein. Certaines d'entre elles sont déjà mergées dans master :
- Nettoyage automatique des nœuds, de façon individualisée
- Le déploiement direct d'interface peut maintenant utiliser un serveur HTTP automatiquement
- Checksum amélioré pour les images Glance
- Parallélisation des effacements de disques
Et les features qui sortiront peut-être à temps pour Stein mais qui sont plutôt à attendre du côté de la release Train :
- Boot HTTP depuis une URL
- Templates de déploiement
- Rendre les étapes de déploiement de nettoyage visibles
- Augmenter la couverture de test du code en Python3
No measurement, no improvement - How to define metrics for CI/CD optimization ?
Shuqan Huang, 99Cloud - www.99cloud.net
Shuqan Huang commence par rappeler que la CI/CD est une approche de l'ingénierie logicielle dont le but est de raccourcir la distance qui sépare le développement d'une nouvelle fonctionnalité de sa mise à disposition à l'utilisateur final après l'avoir testée, ce que l'on appelle en fait le "time to market".
La CI/CD s'inscrit donc tout à fait naturellement dans la démarche DevOps et, pour ne pas perdre en aval le temps gagné en amont grâce à l'agilité, le "pipeline" technique qui sera construit et opéré pour mettre en oeuvre cette CI/CD devra être optimisé de façon continue.
Toutefois, si l'on veut optimiser le pipeline, il faut mesurer ses performances. Comme l'a si bien dit Peter Drucker (professeur austro-américain en management d'entreprise et journaliste financier) : "If you can't measure it, you can't improve it".
D'une manière générale, on a besoin de mesurer pour :
- prendre des décisions
- allouer des ressources (humaines, techniques, financières)
- prévoir des résultats
- estimer la satisfaction des clients
- motiver des équipes
- ...
Mais qu'est-ce qu'une "métrique" ? Et bien tout simplement "une grandeur récupérable et mesurable permettant de suivre au fil du temps la performance d'un aspect spécifique d'un système".
Mais revenons à notre CI/CD. 99Cloud, qui a mis en place un pipeline OpenStack composé notamment de Zuul et Jenkins, fait un constat : les jobs du pipeline sont lents ! Pour quelle(s) raison(s) : le réseau ? Les I/O ? Une première intuition les amène à muscler les machines de build en CPU, RAM et stockage. Les disques durs sont remplacés par des cartes SSD. Mais cela ne suffit pas, il faut mesurer de façon méthodique et rationnelle. Comment ? En décomposant le process de build pour identifier l'opération la plus consommatrice de temps CPU.
En résumé, l'approche méthodologique de Cloud99 a été la suivante :
- un métrique pour chaque aspect du système mesuré
- comprendre les relations entre les différents métriques
- définir de nouveaux métriques de façon continue
- faire des hypothèses et mettre en place des boucles de feedback
Elément stratégique de l'ingénierie logicielle, le pipeline de CI/CD doit rester au service du Time To Market !
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025



