
Deuxième journée de l'Open Infrastructure Summit de Denver, pas de keynotes aujourd'hui, on démarre à 9h dans le dur !
Sessions
Nova Cells v2 update
Les cells Nova permettent de faire des groupes de compute nodes, chaque cell dispose de son propre bus de messages et de sa base de données. Cela permet de passer à l’échelle facilement.
Un cloud OpenStack contient au moins 2 cells :
- cell0 : pour les instances terminées ou en erreur
- une cell par défaut
Un des axes de travail pour Stein était la résilience des cells et notamment comment gérer les cells inaccessibles. La base de données principale de Nova contient ce que l'on appelle les cells mapping. Quand une cell est inaccessible, la requête vers Nova timeout. C'est un problème puisqu'il devrait être possible pour les administrateurs et les utilisateurs d’accéder à des informations même lorsqu'une cell est inaccessible.
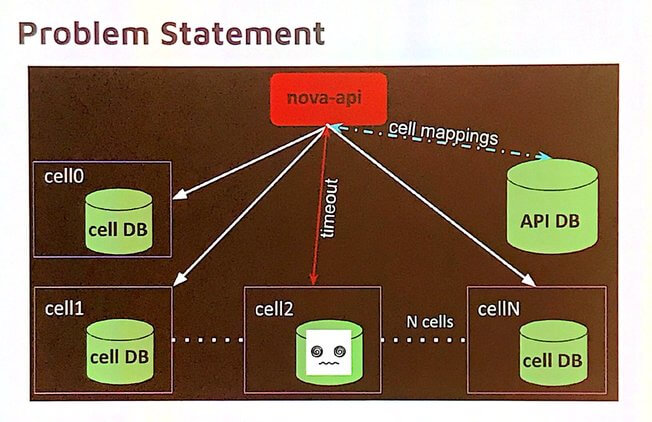
Pour pallier à ce problème, depuis Stein, la solution est de retourner des informations partielles au lieu d'un timeout. Certaines informations des cells sont répliquées dans la base de données principale de Nova et sont retournées dans le cas d'une cell inaccessible. Cela permet :
- De lister les instances
- De voir les informations d'une instance
- De lister les services Nova

Cette fonctionnalité est disponible depuis la microversion API 2.69. Il est également possible de définir un timeout pour le healthcheck des cells avant que Nova ne décide qu'une cell est inaccessible.
Une autre amélioration sur les cells est le calcul des quotas. Par défaut, le calcul des quotas est fait par Nova en parcourant toutes les cells et en agrégeant les résultats. Si une cell est inaccessible, celle-ci est ignorée; lorsque la cell est de nouveau accessible, il est possible pour un projet de se retrouver avec plus de ressources que le quota. Le nouveau mode de calcul se base sur l'API Placement qui est utilisée pour compter la RAM et le CPU. Le nombre d'instances est compté depuis la base de données Nova.
Il existe des petites différences entre les deux modes :
- Les instances en cell0 ne seront pas comptées mais le sont avec le mode legacy.
- Pendant un redimensionnement, le quota est doublé dans le cas où l'on utilise l'API Placement.
Le travail continue pour la prochaine release Train ou les efforts se concentrent sur le redimensionnent des instances entre deux cells. Les cells permettent de segmenter les compute nodes, par exemple en terme de hardware et un administrateur peut avoir le besoin de déplacer des instances d'une cell à une autre.
Le but est de rester au maximum transparent pour les utilisateurs :
- Le workflow de redimensionnement est globalement le même mais le code est nouveau.
- Les administrateurs peuvent réaliser des migrations à froid entre deux cells.
- Les compute nodes sont validés en terme de volumes et de ports Neutron.

Il n'y a pas de communication entre les cells, contrairement au workflow de redimensionnement classique, la majeure partie du travail étant déléguée à Nova-conductor qui peut communiquer avec toutes les cells. Également, il est impossible de copier les disques entre deux cells donc Glance est utilisé en stockage intermédiaire lors d'un redimensionnement.

Comparaison entre le resize classique et entre cells :

Face recognition
Erwan Gallen et Sylvain Bauza (tous deux chez Red Hat) présentent un use case intéressant à faire tourner sur OpenStack, la reconnaissance faciale.
Tout d'abord, afin d'avoir le même vocabulaire, un accent est mis sur la différence entre la détection et la reconnaissance. Ainsi, la détection est une sous-partie de la reconnaissance, celle-ci étant un ensemble de techniques permettant in fine de mettre un nom sur un visage. La détection se contentant de décider si l'objet en question est un visage ou non.
Il existe plusieurs techniques, différents types d'algorithmes, différentes types de réseaux neuronaux pour effectuer cette reconnaissance faciale. Après quelques rappels historiques (on apprend notamment l'existence de ImageNet et DeepNet, le choix retenu pour la reconnaissance faciale est proche du comportement humain, c'est à dire que la machine va se concentrer sur des critères "humains" : coupe de cheveux, lunettes, couleur des yeux, etc. Ces critères sont définis à l'avance par l'algorithme choisi.
La reconnaissance se fait en plusieurs étapes :
- détection et isolation des visages dans l'image
- alignement des visages afin que ceux-ci soient "droits"
- détection des critères de recherche
- un réseau neuronal est créé grâce à ces critères et constitue la "signature" de notre visage
La dernière étape consiste à comparer notre visage inconnu avec une base de données de visages connus. Un seuil est déterminé et si la distance euclidienne entre les deux visages est en dessous du seuil, nos visages sont identiques. Cette partie de la présentation était particulièrement complexe car concernant un domaine qui nous est totalement inconnu. Il est bien possible que nous n'ayons pas parfaitement compris tous les aspects de la reconnaissance faciale...
Et OpenStack là-dedans ? Et bien OpenStack fournit au travers de Nova, une API permettant aux développeurs de pouvoir accéder à des ressources CPU (et surtout GPU) sans avoir à se soucier de la configuration hardware de ces derniers. L'abstraction est toujours un élément important des projets OpenStack. Lorsque l'on veut utiliser un GPU dans une instance, nous avons actuellement deux possibilités. Depuis Havana, il est possible via le pci-passthrough de monter une carte GPU complète directement dans une instance. Cela permet à une instance de prendre complètement le contrôle de la carte GPU. Depuis Queens, Nova intègre la fonction de vGPU qui permet de découper un GPU entre plusieurs instances et ainsi partager le temps GPU.
Le cloud OpenStack du CERN et les conteneurs : cas d'usage et service Magnum
Tim Bell (Cloud architect) et Spyros Trigazis (core developer Magnum), tous deux employés au CERN, nous font un retour d'expérience sur les usages que le CERN fait des conteneurs.
À noter une salle quasiment pleine, environ 180 personnes, signe que pour la communauté OpenStack l'implémentation du CERN reste encore une référence de premier ordre 6 ans après son premier déploiement d'OpenStack en production, release Grizzly, en 2013 !
Tim Bell profite d'ailleurs de l'occasion pour nous rappeler le chemin parcouru depuis cette époque de pionniers en précisant que d'upgrade de release en upgrade de release, le cloud OpenStack en production au CERN est passé de 5 services en 2011 à 14 en 2019 !
La carte d'identité du CERN, Conseil Européen pour la Recherche Nucléaire, qui est en fait le laboratoire de recherche européen pour la physique des particules :
- localisation : Genève
- statut : organisme international
- vocation : recherche fondamentale en physique nucléaire, exploitation du plus puissant accélérateur de particules de la planète.
- ressources humaines : 2 500 personnes en interne pour la conception, la construction et l'exploitation de l'infrastructure de recherche.
- utilisateurs : communauté internationale de plus de 12 000 scientifiques qui exploitent au quotidien les résultats des expériences.
- quelques réalisations clés : le grand collisionneur de hadrons (LHC), la découverte du boson de Higgs en 2012, mais aussi l'invention du World Wide Web par le chercheur britannique Tim Berners-Lee en 1989 !
Tout ceci afin de mieux comprendre le passé et la nature de notre univers, de prévoir son avenir et peut-être un jour enfin de pouvoir en faire une description complète, de l'infini petit à l'infiniment grand ! Et si l'on y parvient, nous pourrons nous rappeler qu'OpenStack y aura apporté sa contribution.
Entrons maintenant dans le vif du sujet. Le CERN a développé et exploité au quotidien le "CERN Container Service" au profit de cas d'usage variés dont nous verrons quelques exemples plus loin. Les technologies clés qui aujourd'hui composent cette plateforme d'infrastructure sont OpenStack release Rocky, Magnum - le service OpenStack de gestion de COE (Container Orchestration Engine) - et le COE Kubernetes.
À noter que le CERN a légèrement modifié le code de Magnum pour l'adapter au plus près de ses besoins et que les lignes de logs qu'il génère sont indexés par ElasticSearch.
Parmi les nombreux cas d'usage du service de conteneurs, citons :
- les traitements par lots (batch processing)
- les analyses utilisateurs finaux (c'est à dire les chercheurs)
- le Machine Learning
- la gestion des infrastructures spécifiques : migration de données, serveurs Web, PaaS
- l'intégration et le déploiement continus (CI/CD)
En fin d'exposé, Spyros Trigazis ne peut s'empêcher de nous rappeler que Magnum est maintenant capable de déployer de grands clusters Kubernetes multi-masters en quelques minutes seulement !
Spyros nous dévoile également quelques "upstream features", c'est-à-dire les éléments de la roadmap fonctionnelle court et moyen terme :
- redimensionnement de cluster : prévu dans la release Train
- groupes de nœuds : pour gérer des clusters de natures différentes
- authentification keystone : utilisable directement via kubectl
- auto-scaling : provisioning automatique de nouveaux nœuds pour héberger les pods
- métrologie : développement d'une solution "out of the box" pour collecter des mesures sur les clusters
- upgrade de cluster : Kubernetes lui-même, les systèmes d'exploitation hôtes et leurs extensions
A propos, pourquoi utiliser Magnum pour déployer et gérer un service de conteneurs ? Là encore, Spyros Trigazis nous apporte des éléments de réponse consistants :
- pour fournir un point d'entrée accessible aux nouveaux venus dans le monde des conteneurs
- pour fournir un service de clusters de conteneurs homogène, centralisé et managé. Se justifie dès que l'on a plus de 5 utilisateurs et plus de 10 clusters à gérer.
- pour contrôler les systèmes d'exploitation utilisés par les utilisateurs
- parce que l'on gagne l'accounting au passage, pour peu que l'on mette en oeuvre les quotas au sein de chaque projet OpenStack
OpenStack/Magnum/Kubernetes, une bien belle réussite de ménage à trois technologique, portée par un fleuron de la recherche scientifique mondiale !
Octavia project update
Un petit tour des nouveautés de ce composant de Load Balancing as a Service.
Parmi les fonctionnalités ajoutées dans la dernière version, Stein, on trouve :
- Octavia flavors : possibilité de définir des modèles réutilisables de load balancer
- Authentification TLS client
- Rechiffrement TLS vers les backends
- Support des tags
Parmi les éléments moins visibles, on notera qu'une partie du code d'Octavia a été isolée dans une bibliothèque dédiée, octavia-lib. Ceci facilite notamment le travail des développeurs de drivers Octavia.
Très rapidement et dès le prochain cycle de développement, Train, quelques travaux sont prévus notamment la capacité pour les composants d'Octavia de reprendre les tâches en cours après une interruption inopinée.
Par ailleurs, neutron-lbaas, ancêtre d'Octavia, va enfin officiellement prendre sa retraite. Il était d'ores et déjà déprécié.
Au-delà de la release Train, il est question de permettre aux utilisateurs de configurer plus finement les ciphers TLS de leurs load-balancers, de supporter le mode actif-actif, ou encore de finaliser l'implémentation de HTTP/2.
Forum
Outils de déploiement OpenStack
Il existe de nombreux outils open source pour déployer et maintenir un cloud OpenStack, une page qui les recense existe déjà : https://www.openstack.org/software/project-navigator/deployment-tools
Mais devant cette multitude de possibilités aucun document de la communauté n'aide à effectuer un choix. On peut aussi ajouter que beaucoup de nouveaux utilisateurs ont d'abord connu Devstack qui permet d'utiliser OpenStack rapidement, mais Devstack n'est pas une solution de déploiement. Le Summit de Denver a permis de recenser les attentes des utilisateurs en termes d'informations à réunir afin d'aider à effectuer ce choix crucial.
Il ressort de la discussion que les utilisateurs souhaitent connaître :
- les choix technologiques de chaque solution
- les OS supportés
- les versions disponibles/stables
- les composants officiellement supportés
- les mécanismes de mise à jour et les possibilités de rollback
- le scaling
- la possibilité d'installer en mode offline, sans connexion internet
Chez alter way Cloud Consulting, nous utilisons principalement OpenStack Ansible (OSA) qui permet de personnaliser la configuration et l'architecture du cluster OpenStack suivant les besoins de nos clients et qui utilise des technologies flexibles, connues et éprouvées comme Ansible et LXC. Nous restons à l'écoute des nouveautés comme notamment Airship qui regroupe les bonnes pratiques du moment.
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025


