Note sur les notions vues dans la suite :
- L'opcode d'une source tels que ceux donnés dans les exemples peut être obtenu avec phpdbg. On charge le fichier à analyser dans le contexte
phpdbg -e /chemin/vers/fichier.php, une fois en mode debug interactif on affiche l'opcode du contexte avec selon le besoin les commandesprint exec,print class Foo\Bar, etc. (cf.help).- L'AST d'un script en PHP 7 est récupérable grâce à l'extension PHP-AST. La notion d'AST n'existe pas nativement en PHP 5 mais la librairie PHP-Parser permet d'en construire un à partir d'une source.
PHPNG, le nouveau moteur
PHPNG (PHP Next Generation), apparu en mai 2014, est venu remplacer le Zend Engine 2 et se voulait en plus d'un grand dépoussiérage une réponse à HHVM développé par Facebook qui donnait de meilleures performances.
La compilateur de PHP 7 repose maintenant sur le principe d'un AST (Abstract Syntax Tree). La génération de cet arbre est une étape supplémentaire dans le processus de compilation pour la génération de l'opcode. L'opcode est un code intermédiaire entre les sources et le langage machine, plus proche de ce dernier ce qui le rend plus rapide à compiler tout en restant indépendant de l'architecture du processeur. Il est ensuite utilisé comme byte code et interprété par la Zend Virtual Machine, principe que l'on retrouve dans de nombreux langages comme Java. Le compilateur est en moyenne plus lent que celui de PHP 5 (globalement plus complexe, utilisation d'un AST). Il est donc recommandé d'utiliser OPCache afin de ne pas être pénalisé à ce niveau.
Optimisations à la compilation
Les évolutions du moteur permettent de réaliser plus d'optimisations lors de la compilation et ainsi obtenir un opcode plus performant. Plusieures de ses optimisations portent notamment sur les expressions statiques.
Résolution des noms de fonction
Dans un espace de nom, ne pas laisser d'ambiguïté sur le nom des fonctions permet un (très) léger gain en évitant de déclencher le système de fallback (cf. règle 7).
Appel de la fonction via fallback
<?php
namespace Foo;
class Bar
{
public function hello($str)
{
return "Hello" . strlen($str);
}
}
L6 #1 RECV 1 $str
L8 #2 EXT_STMT
L8 #3 INIT_NS_FCALL_BY_NAME "Foo\\strlen"
L8 #4 EXT_FCALL_BEGIN
L8 #5 SEND_VAR_EX $str 1
L8 #6 DO_FCALL @1
L8 #7 EXT_FCALL_END
L8 #8 CONCAT "Hello" @1 ~0
L8 #9 RETURN ~0
Appel explicite de la fonction
<?php
namespace Foo;
class Bar
{
public function hello($str)
{
return "Hello" . \strlen($str);
}
}
L6 #1 RECV 1 $str
L8 #2 EXT_STMT
L8 #3 STRLEN $str ~1
L8 #4 CONCAT "Hello" ~1 ~0
L8 #5 RETURN ~0
Argument dynamique vs argument statique
Dynamique
$b = 'foo';
echo strlen($b);
L2 #1 ASSIGN $b "foo"
L3 #3 STRLEN $b ~1
L3 #4 ECHO ~1
Statique
echo strlen('foo');
L2 #1 ECHO 3
Tableaux statiques
Les tableaux contenant des clés et valeurs statiques sont résolus à la compilation et ne consomme plus de temps à l'éxécution.
$a = ['bar', 'baz', 'foo', 34, [42, 'bar' => 'baz']];
PHP 5
0 E> INIT_ARRAY ~0 'bar'
1 ADD_ARRAY_ELEMENT ~0 'baz'
2 ADD_ARRAY_ELEMENT ~0 'foo'
3 ADD_ARRAY_ELEMENT ~0 34
4 INIT_ARRAY ~1 42
5 ADD_ARRAY_ELEMENT ~1 'bar', 'baz'
6 ADD_ARRAY_ELEMENT ~0 ~1
7 ASSIGN $a !0, ~0
PHP 7
L2 #1 ASSIGN $a array(5)
Mécanismes internes
Gestion des variables
Toutes les variables de PHP sont stockées dans des structures zval encapsulant les différentes informations nécessaires (type de variable, information pour le garbage collector, etc.).
Des changements sur la façon de gérer ce stockage ont été opérés.
| PHP 5 | PHP 7 |
|---|---|
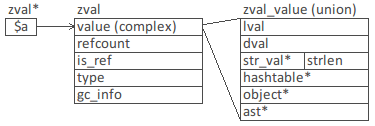 |
 |
| 2 indirections 40 octets + taille de la valeur complexe |
1 indirection 16 octets + taille de la valeur complexe |
Ce qui conduit aux optimisations suivantes :
- taille de stockage moins importante (donc gestion cache plus efficace)
- réduction du nombre d'indirections au niveau des pointeurs pour retrouver une valeur
- possibilité de partager les types complexes au lieu des
zvalles contenant - allocation en mémoire plus simple, couplé au remplacement de
malloc()parmmap()qui ici offre de meilleures performances - meilleure utilisation de la TLB
Gestion des références
Plusieures améliorations sur les mécanismes gérant les références. PHP utilise le principe COW (copy-on-write) c'est à dire que lors d'une affectation d'une variable vers une autre ou un passage par valeur dans une fonction/méthode, la valeur ne sera copiée que lors d'une opération d'écriture permettant ainsi d'éviter une duplication inutile (d'où gain de mémoire et de temps CPU). Le principe de reference mismatching (i.e. passer un argument par valeur alors qu'il est attendu par référence ou l'inverse) cassait parfois ce principe comme dans l'exemple ci-dessous :
function foo($arg) {/* ... */}
$a = 'foo';
$b =& $a;
foo($a)
En PHP 5 ce genre d'appel déclenchait une copie complète de la variable dès l'appel de la fonction. En PHP 7, le principe COW est mieux respecté et une copie ne sera cette fois faite que lors d'une éventuelle modification.
Tableaux
Table de hachage
La gestion des tables de hachage a bénéficié d'amélioration sur la façon de stocker les données, de la même façon que l'on avait déjà une amélioration au niveau de la structure zval.
| PHP 5 | PHP 7 |
|---|---|
 |
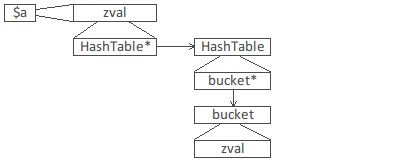 |
| 4 indirections 72 octets pour bucket |
2 indirections 32 octets pour bucket |
Notion de packed arrays
Un packed array est un tableau dont
- toutes les clés sont des entiers
- les clés sont strictement croissantes (pas nécessairement de 1 en 1)
Dans ce cas, on bénéficie d'une réduction de la mémoire utilisée, de l'ordre de 4Ko pour 1000 entrées. Sur des tableaux très grands, le gain peut devenir significatif.
Gestion des chaînes
Interned string
La notion d'interned string a été introduite par les langages fonctionnels et notamment Lisp.
L'idée est que chaque chaîne est immutable et n'est allouée qu'une seule fois en mémoire.
En PHP 5, les chaînes n'ont pas leur propre structure mais sont encapsulées dans la structure zval, ce qui complique leur gestion et conduit à de nombreuses duplications inutiles.
Pour corriger cette faiblesse, la structure zend_string a été introduite et permet de bénéficier de plusieurs améliorations :
- notion de refcount (comme pour les
zval) elles sont ainsi partageables et bénéficient du principe COW - hash précalculé, éventuellement à la compilation quand c'est possible
L'utilisation d'OPCache apporte un plus au niveau de la gestion des chaînes, car il offre un partage de celles-ci entre les processus.
Ce point est donc particulièrement utile dans le cas de PHP-FPM qui fonctionne sur un principe de fork et les stocke dans le processus père.
La mémoire allouée à ces chaînes est paramétrable via la directive de configuration opcache.interned_strings_buffer.
Dans le cas de Symfony cette notion de interned strings est une amélioration notable car elle recouvre beaucoup de cas (constantes, noms de classes, annotations, …).
Pour cette raison, il est conseillé d'augmenter la valeur de buffer – un peu faible par défaut – à au moins 16Mo.
Encapsed string
Il s'agit des chaînes entre double-quote qui nécessite d'être analysées pour résoudre les variables qu'elles contiennent.
$a = "foo and $b and $c";
PHP 5
0 E> ADD_STRING ~0 'foo+and+'
1 ADD_VAR ~0 ~0, !1
2 ADD_STRING ~0 ~0,'+and+'
3 ADD_VAR ~0 ~0, !2
4 ASSIGN !0, ~0
5 RETURN 1
Réallocation de mémoire à chaque étape entraînant de mauvaises performances.
PHP 7
L2 #1 ROPE_INIT "foo and " ~1
L2 #2 ROPE_ADD ~1 $b ~1
L2 #3 ROPE_ADD ~1 " and " ~1
L2 #4 ROPE_END ~1 $c ~0
L2 #5 ASSIGN $a ~0
L3 #6 RETURN 1
Garde chaque chaîne dans un buffer propre et fait un seul merge final.
Contrairement à une idée répandue, il est donc recommandé d'utiliser les encapsed string plutôt que la concaténation lorsque des variables entre en jeu dans une chaîne.
$a = "foo and $b and $c"; // OK
$a = 'foo and ' . $b . ' and ' . $c; // KO
À venir
PHP 7.2 est en cours et arrivera courant décembre 2017. Les nouveautés et optimisations continuent à être ajoutées, elles sont consultables dans les RFC.
Un des principaux travaux en cours est de pouvoir fournir un compilateur JIT (Just In Time). Initialement prévue pour PHP 7, cette nouvelle étape devrait arriver pour PHP 8 qui n'est pas annoncé avant 2020 (au mieux). Dans les grandes lignes, le principe est d'effectuer une compilation à la volée de l'opcode et de mettre en cache le code machine résultant permettant encore de gagner en performances.
Pour appronfondir les notions vues, se reporter aux liens suivants :
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025



