
- Qu'est-ce qu'Amazon S3 : Simple Storage Service ?
- 5 choses que vous ignoriez (peut-être) sur Amazon S3 : Simple Storage Service!
- Réaliser une application sans instance avec Amazon S3

Amazon S3 : Exemple concret avec S3 !
Après avoir passé en revue les différentes classes de stockages proposées par Amazon S3 et nous être familiarisés avec la terminologie AWS puis avoir testé nos connaissances sur S3, il est temps de passer à un cas concret !
Cet article à pour but de vous guider au travers d'un cas concret d'une application sans instance reposant sur les capacités d'Amazon S3. Ce cas d'école se base sur un talk de l'AWS Re:Invent 2015 auquel nous avons assistés et dont vous pourrez retrouver la capture vidéo sur Youtube.
Ma startup : VidShare !
Au cours de cet article, nous allons mettre une place une platforme de partage de vidéo (de vacances bien sûr) avec sa famille et ses amis. Pour assurer la réussite de mon projet, j'ai identifié quelques pré-requis :
- Etre capable de tenir la charge (faire évoluer la plateforme en fonction du nombre d'utilisateurs);
- Pouvoir toucher plusieurs marchés dès le lancement : Europe et USA,
- Avoir une plateforme à faible coût et faible latence.
Le projet s’effectue en quatre phases :
- Une phase de lancement destinée à la mise en place de l'architecture et des mécanismes ;
- Une v2 destinée ptimisation du coût de stockage et à la gestion des cycles de vie ;
- Une v3 avec l’utilisation des CDN ;
- Et enfin une v4 adaptée aux entreprises.

V1 : mise en place de l'architecture et des mécanismes d'Amazon S3.
Notre premier besoin est de pouvoir uploader des vidéos sur Amazon S3. Une fois le fichier en ligne, il va faloir qu'un certain nombre d'actions se lancent : il faut redimensionner les vidéos, créer des thumbnails, indéxer tout ça dans dynamoDB afin de rendre les vidéos disponibles à la relecture, puis envoyer une notifications à mes amis pour leur dire que la vidéo est disponible.
Nous allons pour cela reposer sur deux services AWS qui permettent de remplir ces conditions : Amazon S3 et AWS Lambda, un service de calcul qui exécute du code en réponse à des évènements automatiques.
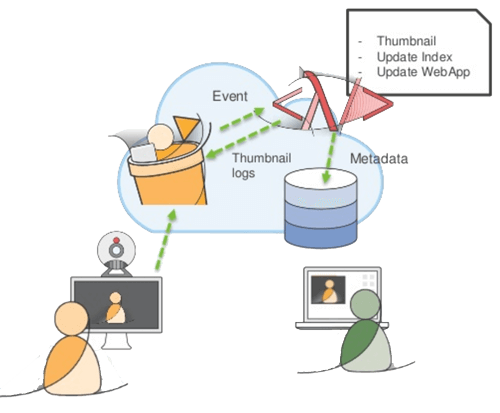
Pour utiliser la propriété “event” du bucket S3, il suffit de se référer à l'onglet "Events" des propriétés du Bucket qui va recevoir les vidéos.
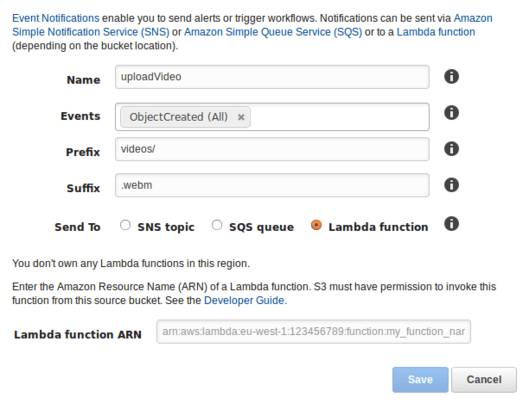
Dans cet onglet, nous pouvons associer un certain nombre d'actions à des événements du bucket : put, post, copy, complete et delete. Ces actions seront executés par Amazon Lambda : à l'événement "ObjectCreated" - l'upload d'une vidéo - nous allons lancer une fonction lambda (rédigée au préalable).
Les données des vidéos sont alors transférées sur DynamoDB, mais il est aussi possible de configurer des events en cas de suppression de vidéos.
V2 : Optimisation du coût de stockage, gestion des cycles de vie.
Ici, on s’attaque à la version 2 du projet, l’optimisation des coûts. Avec l’apparition d’un nouveau type de stockage dans Amazon S3 (Infrequent Access Storage) il est possible de gérer la manière dont le stockage objet est effectué.
Avec la gestion du cycle de vie des buckets on peut définir le type de stockage que l’on applique : (Standard? Infrequent Access? Glacier? ).

Pour faire simple, une vidéo récente sera placée dans un stockage standard, alors qu’une vidéo plus ancienne en Infrequent Access, après 30 jours de stockage dit standard. Enfin après une année, on archive cette vidéo dans glacier.
Cela a pour but de diminuer de manière effective les coûts de stockage.
Ci dessous un exemple de lifecycle policy :

Il est possible de le configurer de manière très simple, via la console AWS, et le Lifecycle Rule :
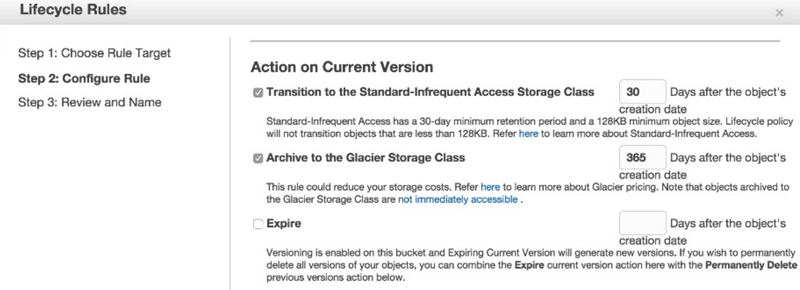
Concrètement :
Pour ce qui est du coût, estimons qu’il y ait 1 Po de vidéos sur S3 standard, cela reviendrait a 28 816 $. En transférant les vidéos plus anciennes dans Amazon S3 standard IA, cela reviendrait alors a 17 600$.
Une économie de 39% sur le stockage des données dans cet exemple, bien identifier les besoins de stockage un point clé de l’utilisation de S3.
V3 : Etendre Vidshare au monde entier !
La troisième étape du projet, serait de développer la distribution du contenu via différentes régions du monde, et avec très peu de latence.
C’est ici qu’entre en jeux Amazon S3 cross-region replication :
Cette option d’Amazon S3 prend effet au niveau du bucket, cette fonctionnalité permet de répliquer les buckets à travers différentes régions AWS. Le versionning doit être activé sur les buckets, et les objets déjà répliqués ne le seront pas une seconde fois.

voici les étapes :
- 1 . Il faut deux bucket (si l’on souhaite répliquer le contenue de la région A vers la région B).
- 2 . Activer le “versionning” sur les deux buckets.
- 3 . Créer un Rôle IAM pour le compte A.
- 4 . Ajouter la configuration de réplication sur le bucket source, c’est à dire le Bucket A.
V4 : “Vidshare version Entreprise”
Ici il est question d’appliquer l’infrastructure de “Vidshare” dans un environnement AWS isolé selon les bonnes pratiques AWS, notamment avec l’utilisation des VPC.
Pour rappel Amazon Virtual Private Cloud permet d’isoler de manière logique une partie du cloud AWS, dans laquelle il est possible de lancer des ressources AWS. C’est un réseau virtuel que l’on définit nous même, que ce soit au niveau des plages d’adresse IP, la création des sous réseaux et la configuration des tables de routages, VPN, passerelles etc…
Ici, il sera question du VPC endpoint, qui va permettre de raccorder un réseau privé à S3.
Voici le schéma d’utilisation d’un S3 VPC endpoints :
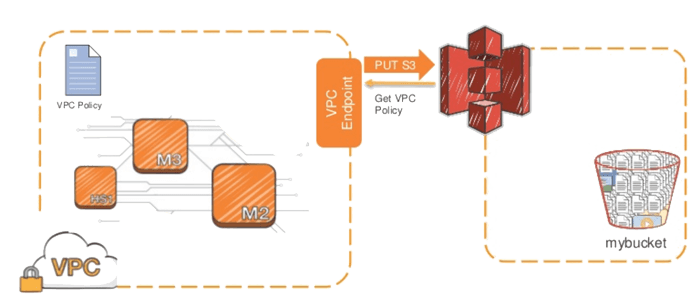
L’utilisation à la fois de S3 et des VPC endpoints permet de facilement délimiter les accès à un bucket S3 par l’utilisation conjointe d’une “VPC-policy” et d’une “S3 bucket policy”
Les avantages de coupler ces deux services Amazon :
- Facile à mettre en place, pas besoin de manager du NAT.
- Haute disponibilité des ressources depuis le VPC vers Amazon S3
- Reduction des coûts (pas de NAT par exemple).
- Sécurité accrue, pas besoin de router le trafic vers Internet.
- Un contrôle de l’accès au buckets accru, puisque l’on définit l’accès selon un VPC bien précis.
Voici un exemple de VPC Policy, permettant de restreindre l’accès à un Bucket :

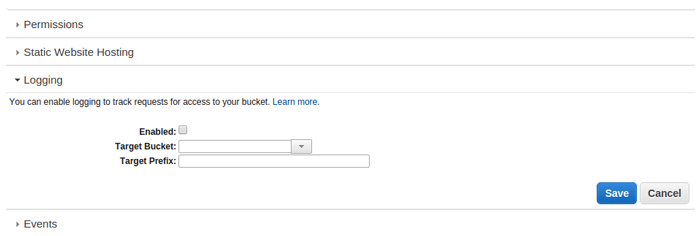
Et les logs dans tout ça ?
Enfin, il est aussi possible de répertorier les actions sur les différents buckets Amazon S3, que ce soit la création d’objet, la suppression, les changements d’accès, les politiques d’accès etc. Ici on souligne le contrôle laissé à l’utilisateur quant à l’utilisation de son infra AWS.
Activation des Logs dans S3 :
Amazon S3 : la suite du dossier :
- Qu'est-ce qu'Amazon S3 : Simple Storage Service ?
- 5 choses que vous ignoriez (peut-être) sur Amazon S3 : Simple Storage Service!
D'autres articles sur AWS :
- Serverless avec AWS : cas concret
- Amazon Web Services : une infrastructure mondiale
- Amazon Web Services : Comment fonctionnent les Réservations d'instances ?
- A la découverte d'AWS Lambda
Rejoignez vous aussi la conversation !
- Questions, remarques, suggestions... Contactez-nous directement sur Twitter sur @osones !
- Pour discuter avec nous de vos projets, nous sommes disponibles directement via contact@osones.com !
- Rejoignez VOTRE groupe LinkedIn dès maintenant : Utilisateurs Francophones d'Amazon Web Services (AWS).

Lionel Daubichon
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025


