
Osones vous propose de vivre le Summit OpenStack 2016 d'Austin, Texas !
-
Vous pouvez retrouver sur le blog le récit de la première journée de l'OpenStack Summit Austin, celui de la deuxième journée et celui de la troisième journée.
-
Nous avons également mis à jour nos supports de formation OpenStack et Docker. Ces supports sont bien entendu en français, et disponibles sous licence Creative Commons BY-SA !
Dernière journée avec conférences et sessions design. En effet, le vendredi sera entièrement consacré aux contributors meetups, des sessions de travail d'une demi-journée pour chacun des projets OpenStack. Autrrement dit, les dernières conférences avaient lieu aujourd'hui.

Design sessions
Working group des ambassadeurs
Mais que se passe-t-il dans un working group d'ambassadeurs ?
Pour rappels, les ambassadeurs OpenStack sont des gens reconnus par la Fondation et impliqués dans un ou plusieurs groupes d'utilisateurs locaux. Ils ont l'expérience et le réseau nécessaire pour aider les organisateurs de groupes d'utilisateurs et servent aussi de relai avec la Fondation. Chaque ambassadeur est associé à une région (Amérique de Nord, Europe, etc.). Il y a par exemple 3 ambassadeurs en Europe.
Cette session était l'occasion de synchroniser les différents acteurs des groupes d'utilisateurs à travers le monde et les ambassadeurs. Plusieurs points ont été remontés :
** Comment les groupes d'utilisateurs financent-ils les OpenStack Days ?**
Les différents pays ont remontés leurs difficultés ou leurs astuces pour financer les OpenStack Days.
- Le Japon, la Russie, Taiwan, Houston, la Chine, la Corée du Sud, l'Allemagne font appels à des sociétés privées qui gèrent le financement des événements. Ces sociétés gèrent le délai habituel entre le moment ou le groupe d'utilisateur payent les factures, et le moment ou les sponsors envoient réellement l'argent.
- En France, les meetups ne coûtent pas autant que les OpenStack Days. Il y a habituellement un seul sponsor qui paye à l'avance. Le problème sera tout de même présent lors d'un éventuel OpenStack Day à la fin de l'année.
** Comment démarrer un groupe d'utilisateurs sans financement ? **
Pour certains nouveaux groupes d'utilisateurs, trouver des sponsors dès le démarrage peut s'avérer complexe. Une proposition discutée est d'organiser des parrainages / jumelages avec un autre groupe d'utilisateur bien établi et avec des sponsors afin d'en faire profiter
Quels sont les canaux officiels de communication entre les Ambassadeurs et les groupes d'utilisateurs ?
- La mailing list Community : community@lists.openstack.org
- Un canal IRC : #openstack-community sur Freenode
**Y a-t-il assez d'ambassadeurs dans le monde ? **
Clairement, une région comme l'Afrique a besoin d'un ambassadeur. Aussi, si certains ambassadeurs ont plus de travail que d'autres, il a été rappelé que rien n'empêche à un ambasseur d'une région d'aider un groupe d'utilisateurs d'une autre région.
Et encore ?
Les ambassadeurs ont remonté leurs difficultés à faire des réunions IRC régulièrement, les timezones des différents ambassadeurs étant très différentes, dû à la nature même de leur activité. Lors des prochains summits, il a été évoqué la possibilité de faire une session de feedback entre les ambassadeurs et les leaders des différents groupes d'utilisateurs.

La session des ambassadeurs en live
Conférences
OpenStack Elastic Load Balancing : passer à la vitesse supérieure avec Neutron LBaaS V2.0 et Octavia - IBM, HPE, Bluebox
En introduction de cette présentation, les intervenants rappellent que le projet est bien structuré, soutenu par des poids lourds de l'industrie et que le Load Balancing arrive en tête des services réseau (Neutron) attendus par les utilisateurs.
Neutron LBaaS v2.0
Du côté des nouvelles fonctionnalités, le routage basé sur le contenu de la requête HTTP (L7 Content Switching) sera achevé dans le cycle de release Newton. Avec le L7 Content Switching, il est possible d'exprimer des règles que l'on peut regrouper en "policies". Ces règles peuvent s'appliquer à l'URL elle-même, aux cookies ou bien à un champ du header HTTP. Elles sont de type booléen. Elles sont connectées entre elles par un "et" logique et l'action associée (REJECT, REDIRECT_TO_POOL, REDIRECT_URL,...) n'est déclenchée que si toutes sont évaluées à "vrai". Si l'on a besoin d'un "ou" entre règles, il est nécessaire de créer une autre policy.
Notons qu'avec LBaaS v2.0 il est possible de partager un pool (de serveurs load balancés) entre plusieurs listeners.

La photo bi-annuelle OpenStack-fr
Octavia
Côté moteur de load balancing, la technologie Octavia, actuellement en cours de développement, associée à Amphora, le composant qui réalise le load balancing effectif, ambitionne de jouer dans la cour des grands en se positionnant comme une technologie de load balancing "operator grade". Au-delà de son design control plane/data plane, la roadmap d'Octavia (Newton et au-delà) nous promet :
- la haute disponibilité du control plane
- le clustering actif/actif
- la scalabité horizontale
- le support des conteneurs
Par ailleurs, Octavia permet de simplifier certaines actions. En effet, une commande suffit pour :
- supprimer en cascade un load balancer et ses pools de membres
- créer un load balancer --> "Get-Me-A-Load-Balancer" (listeners, pools, members, health monitors, L7 policies)
And last but not least, Octavia nous offre :
- la transition entre le mode actif et le mode passif en quelques secondes
- l'anti-affinité optionnelle pour les instances actives et passives à l'aide du filtre d'anti-affinité de Nova
- une instance en échec automatiquement reconstruite en utilisant le "failover flow" d'Amphora
- les "tags" de Glance pour modifier l'image de boot d'Amphora sans redémarrer Octavia
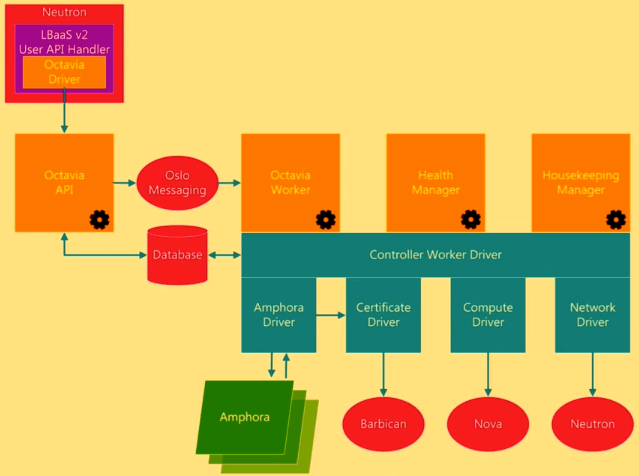
Enfin, si vous souhaitez tester LBaaS v2.0 et Octavia dans DevStack, il vous faudra activer les options enable_plugin neutron-lbaas enable_plugin octavia dans le fichier localrc.
Neutron DVR : haute disponibilité du SNAT
À Tokyo, dans les working groups Neutron du design summit, il était question de la distribution des fonctions réseau de Neutron. Depuis l'introduction du DVR (Distributed Virtual Router), la plupart des fonctions de Neutron sont distribuées sur les nœuds de compute :
- neutron-l3-agent
- neutron-metadata
- DNAT pour les floating IP
- neutron-metadata-agent
Il reste certains services centralisés sur des nœuds dédiés tels que le DHCP et notamment le source NAT (dvr_snat).
Comment distribuer le SNAT de la même manière que les DNAT (floating IP) ? Certains éléments de réponse ont été évoqués à Tokyo et la discussion continue à Austin.
Actuellement, dans le cas d'un déploiement Neutron DVR, la partie assurant le source NAT (pour les instances ne disposant pas de floating IP) n'est pas redondante et est présente sur un nœud dédié (typiquement sur les contrôleurs).
La solution présentée aujourd'hui n'est pas vraiment un SNAT distribué mais plutôt une HA : il n'est pas question de supprimer les composants réseau des contrôleurs/network nodes pour les distribuer sur les computes mais d'assurer une redondance du service dvr_snat sur plusieurs contrôleurs ou network nodes.
La HA pour DVR SNAT reprend le concept de HA sans DVR utilisé par le legacy SNAT :
- un qrouter actif est créé pour le SNAT, d'autres qrouters sont également créés en passif sur les autres contrôleurs/network nodes
- keepalived est utilisé pour détecter la défaillance d'un nœud et router le trafic vers un nœud sain
C'est une solution plutôt simple et déjà éprouvée. Contrairement aux autres services complètements distribués, elle n'enlève pas l'utilisation de nœud dédié pour le SNAT (même si la pratique actuelle est de le placer sur les contrôleurs qui sont aux moins 3 en HA dans un environnement de production), et ne résiste pas au passage à l'échelle. Enfin, la HA ne concerne que le composant dvr_snat et non pas les autres services, tels que le DHCP ou le VPNaaS par exemple.
Petit bémol pour les environnements déjà en production : comme souvent, l'upgrade en mode DVRHA depuis un autre type de routeur Neutron n'est pour le moment pas supporté sans interruption de service.
Pour la release Newton, d'autres améliorations du DVR sont prévues, notamment :
- Implémentation des BGP speakers
- Trafic nord/sud complètement distribué dans le cas d'IPv6

Neutron LBaaS v2 : Nouveautés et intégration avec Heat
LBaaS v1 est déprécié depuis Liberty, plus rien ne sera mergé dans LBaaS v1, il faut migrer en LBaaS v2, c'est le rappel fait tout au long de cette conférence.
Qu'est ce que LBaaS v2 ? Contrairement à la première version, la version 2 est devenue un projet séparé du cœur de Neutron (neutron-lbaas), c'est une complète réécriture et aucune compatibilité n'est présente entre les deux versions.
LBaaS v2 est stable depuis Mitaka et propose les fonctionnalités suivantes :
- Architecture pluggable : Octavia, VMware, Brocade, F5, A10, etc.
- Integré à OpenStack CLI depuis Mitaka
- Le backend officiel est Octavia.
Qu'est ce qu'Octavia ? Octavia est l'implémentation de load balancer par defaut de LBaaS v2, elle repose sur HA Proxy, fonctionnant dans des instances (contrairement à LBaaS v1) appellées Amphora, pour le moment en mode actif ou actif/passif.
La création et l'utilisation d'un load-balancer sont décomposées en plusieurs ressources, ces ressources ont été ajoutées dans la version Mitaka des templates Heat :
- Load Balancer : dirige le trafic entre différents pools, dispose d'une VIP
- Listener : Endpoint d'une VIP, correspond à un protocole (TCP, HTTP, HTTPS) et un port
- Pool : Groupe de serveurs qui correspond à un sous réseau ainsi qu'un algorithme de load balancing
- Pool Member : Correspond à une IP et un port et n'est pas nécessairement une instance Nova
- Health monitor : Correspond à une méthode (PING, HTTP, TCP), un pool, et des paramètres (delay, timeout retries)
Ces éléments sont bien sûr intrinsèquement liés mais pour le moment, à moins d'utiliser le dashboard Horizon, ils doivent être créés, reliés et supprimés séparément. L'utilisation de Heat pour provisionner des load balancers permet de s'affranchir de cette contrainte, puisque Heat permet une gestion cohérente (en cascade) des ressources d'une stack, ainsi qu'une suppression propre de tous les éléments au moment de la destruction de la stack.
Pour les cycles Newton et après, il y a déjà beaucoup de considérations :
- Étendre les plugins
- Intégration à la CLI OpenStack
- Amélioration sur Octavia
- L7 : content based routing
- Partage de pool
- Rotation des certificats
- API : Création et suppression en cascade (workaround en utilisant Heat comme vu précédemment)
- Amphora : mode actif/actif, implémentation via conteneurs au lieu d'instances
Le projet Calico
Des projets SDN ce n'est pas ce qu'il manque, mais celui-ci mérite de s'attarder un moment.
Calico se veut simple, son premier (et presque unique) rôle est d'apporter de la connectivité IP entre les réseaux. Ainsi il se base uniquement sur un L3 et ne fournit absolument aucun L2. Au premier abord, cela veut dire pas de broadcast et donc pas de DHCP et pas d'ARP. Ces fonctions sont néanmoins assurées par d'autres biais. Depuis peu Neutron dispose d'un attribut (l2_adjacency) qui permet de spécifier si un réseau propose ou non un L2. Calico utilise cet attribut car il fonctionne uniquement en L3.
Un agent Calico (appelé Felix) est présent sur chaque node et assure une fonction de proxy ARP. Chaque instance est connectée à une interface TAP. Lorsque l'instance A souhaite joindre l'instance B, une requête ARP sera émise et c'est Felix qui y répondra. Le node en question possède via Felix une table de routage lui indiquant sur quel node se situe l'instance de destination. Ce routage est assurée via un process BIRD avec BGP. Une fois le paquet arrivé au node de destination, celui-ci, grâce à son agent Felix déterminera sur quelle interface TAP il doit router le paquet pour finalement atteindre l'instance de destination.
Du fait que Calico apporte une connectivité "totale" sans NAT, le plan d'adressage IP doit être maintenu. Ce qui peut paraître une contrainte n'en est pas une, puisque même dans le cas d'un réseau NATé, un plan d'adressage doit tout de même être géré ne serait-ce que pour la communication interne où l'overlap ne peut être permis. L'isolation entre réseaux jusqu'à présent assuré par le NAT et les network namespaces doit désormais être gérée par les security groups. Encore une fois, les choix de Calico visent à fournir de la connectivité IP end to end comme cela est en train de devenir un standard dans les réseaux en datacenter.
L'utilisation de BGP permet notamment une intégration aisée avec une fabric IP qui emploie très régulièrement ce protocole de routage.
-
Retrouver le sommaire de ce dossier sur le récit de la première journée de l'OpenStack Summit Austin.
-
Le cinquième jour de l'OpenStack Summit, c'est par ici !
L'équipe Osones
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025



