
C'est parti pour le résumé de notre deuxième journée à la KubeCon/CloudNativeCon Europe 2019. Si vous avez raté la première, rendez-vous ici.
Breakout Sessions
Resize your pods without disruption
Karol Goab (Google) Beata Skiba (Google)
Kubernetes permet de gérer les ressources CPU/RAM allouées aux conteneurs des pods. Il en existe deux types :
- les réservations : le scheduler garantit que le pod sera schedulé sur un nœud disposant des ressources adéquates
- les limites : limite haute de CPU/RAM, en cas de dépassement de mémoire, le pods sera OOMKilled. Dans le cas du CPU, le pod sera throttled
La consommation de ressources peut cependant évoluer avec le temps :
- en fonction des patterns d'utilisation
- en fonction du nombre d'utilisateurs (hausse)
- en fonction du comportement de l'application
Pour ne pas avoir à gérer ces changements à la main, il existe un composant : Vertical Cluster Autoscaler qui permet d'adapter automatiquement les réservations CPU/RAM des pods.
En pratique, le Vertical Autoscaler :
- observe la consommation des pods
- crée des recommandations
- met à jour les ressources (optionnel)
Le Vertical Autoscaler propose différents modes :
- Off : recommandations seulement
- Initial : application des recommandations à la creation du pod
- Auto : mise à jour des pods en fonction des recommandations
Actuellement, pour changer les limites et réservations CPU/RAM d'un pod il est nécessaire de le redémarrer. Cela peut présenter un point bloquant suivant le type de workload. L'objectif est de permettre un redimensionnement dynamique des containers sans avoir besoin de le redémarrer les pods, afin de pallier à ce problème.
Pour le moment, les ressources des pods sont des champs immuables dans l'API, il est impossible de modifier les ressources sans recréer le pod. Comment résoudre le problème ? Simplement en rendant le champ modifiable.
Cela peut sembler simple en théorie, mais du point de vue Kubernetes c'est un breaking change qui impacte plusieurs composants, dont le Kubelet et le scheduler. Une KEP (Kubernetes Enhancement Proposal) est en cours.
Le workflow serait le suivant :
- une demande de resize est appliquée
- l'admission controller ResourceQuota valide la demande
- l'API-Server stocke l'objet dans etcd
- le scheduler vérifie que les ressources sont bien disponibles
- le kubelet effectue la modification en appliquant les changements sur les cgroups
Cette proposition génère des changements dans la spécification des pods et ajoute deux champs.
ResizePolicy
- NoRestart (default)
- RestartContainer : redémarre uniquement le conteneur au sein du pod
- RestartPod : détruit et recrée le pods (en repassant par le scheduler)
RetryPolicy :
- NoRetry (default)
- RetryUpdate : boucle indéfiniment
- Reschedule : reschedule le pod si le redimensionnement ne fonctionne pas
Cette fonctionnalité permettrait donc de minimiser les interruptions de services ainsi que d'avoir des réservations de ressources en phase avec le besoin réel des micro services.
Pour le Vertical Autoscaler, deux nouveaux modes seraient disponibles :
- In-place only : Application automatique des modifications uniquement avec un redimensionnement à chaud
- In- place preferred (auto) : Application automatique des modifications avec un redimensionnement à chaud et bascule sur un redémarrage si le redimensionnement échoue
C'est dur mais on s'y tient. Écriture du résumé de la deuxième journée sur le blog. #Kubernetes #kubecon2019 pic.twitter.com/JmhsjI0ER3
— Pierre Freund (@PierreFreund_AW) 22 mai 2019
The Serverless Landscape
Arun Gupta @AWS Dee Kumar @CNCF
Cette session était l'occasion de revenir sur les fondamentaux du serverless, et comment ces technologies s'inscrivent dans la CNCF. En d'autres termes, comment la CNCF gère-t-elle les problématiques de serverless, alors qu'aucun standard technologique ne semble émerger.
Rappelons tout d’abord 4 règles lorsque l'on parle de serverless. Les caractéristiques de ce genre de service sont :
- Pas d'infrastructure : l'infrastructure n'est pas élément apparent pour l'utilisateur. Il n'y a pas de management, pas de cycle de vie, pas de patch, pas de mise à jour, etc.
- Scaling automatique : une application sur un service serverless doit pouvoir scaler automatiquement, sans modification du code. Une application doit pouvoir passer de 10 à 100 requêtes par seconde, voir même 1000, sans aucune reconfiguration.
- Haute disponibilité : le service serverless doit être hautement disponible. C'est le service qui assure la haute disponibilité de l'application, et non l'application elle-même.
- Pay for value : le modèle de facturation n'est pas lié à l'infrastructure utilisée, que ce soit du compute, du réseau ou du stockage. C'est bien le temps d’exécution des fonctions qui est facturé.
Cette session a attiré beaucoup de monde, bien que les problématiques de serverless ne semblent pas être le sujet principal d'un événement plutôt tourné vers les conteneurs et Kubernetes.
Une salle bien remplie pour suivre une présentation sur le #serverless à la #kubecon2019.
— Pierre Freund (@PierreFreund_AW) 22 mai 2019
Résumé à découvrir ce soir sur le blog @alterway !
👉 https://t.co/SZkS7hdueu pic.twitter.com/aXpFFw4eIn
Lors de cette présentation, les fonctionnalités d'AWS Lambda ont été présentés. A noter que les langages supportés aujourd'hui sont les suivants :
- node
- python
- java
- ruby
- .net
- go
- powershell
Mais il y en a d'autres, car lambda propose le portage de langage. Des sociétés spécialisées ont donc porté des langages comme Cobol. Oui, oui : pour faire du Cobol serverless.
Autre sujet intéressant, il existe un design pattern pour passer les applications legacy en application serverless. Ce pattern s'appelle "The Strangler Pattern". Il décrit la procédure pour transformer une application monolithique en microservices, en transformant petit à petit les composants legacy des applications en événements pour les APIs.
Mais quel rapport avec la CNCF me direz-vous ? Et vous aurez raison.
La CNCF a un Working Group (WG) sur le Serverless. Celui-ci travaille sur la spécification des "CloudEvents". La problématique pour le serverless n'est pas de définir un standard de conception des services. Chaque cloud provider dispose de son propre système, comme Lambda pour AWS, qui est différent du service équivalent sur GCP ou Azure. La CNCF travaille donc sur le standard d'échange entre ces services.
En effet, nous vivons dans un monde multi-cloud. Chaque cloud a ses propres particularités, avantages et inconvénients. Mais alors comment faire dialoguer des services sur des clouds différents ? Comment faire une architecture qui utilise Google Cloud Storage en déclanchant de l'AWS Lambda ? Est-ce possible ? La réponse est oui, via les "Cloud Events".
C'est par ce biais qu'une interopérabilité des clouds sera possible dans le monde serverless.
Enfin, vous pouvez lister les technologies serverless dans le landscape de la CNCF, pour cela rendez-vous sur : s.cncf.io

The Magic of Kubernetes Self-Healing Capabilities
Saad Ali (Google)
Comme dans tout système, et encore plus dans tout système complexe, une panne risque toujours d'apparaître. Or, les tailles des systèmes utilisés rendent très compliqué, voire impossible, de gérer la plupart des problèmes simplement à la main. D'où la nécessité d'un outil d'automatisation comme Kubernetes et sa capacité de self-healing.
Le self-healing de Kubernetes repose sur deux spécificités :
- une API déclarative
- les contrôleurs.
Une API déclarative
Kubernetes repose sur une API déclarative. Quelles sont les spécificités d'un tel type API par rapport à une API impérative et pourquoi avoir choisi d'implémenter l'API de cette façon ?
Une API impérative spécifie exactement ce que le système doit faire. Ceci pose problème lorsque une panne survient. Il faut alors investiguer et réparer manuellement ce qui ne fonctionne plus. Ce qui peut être plutôt fastidieux et compliqué.
Au contraire, dans une API déclarative, l'utilisateur spécifie l'état dans lequel doit se trouver le système. Celui-ci fait alors en sorte d'y correspondre. Sans intervention supplémentaire.
Les bénéfices d'une API déclarative sont alors les suivants :
- pas de single point of failure
- pas de problèmes de type "événement manquant/étape manquante"
- des composants simples
- une restauration automatique.
Ce qui se traduit donc en un système plus simple, plus robuste et qui peut plus facilement récupérer de la panne de l'un de ses composants.
Les contrôleurs
Les contrôleurs sont composés de deux parties, un cache et une boucle de contrôle. Ils permettent de vérifier et de modifier les états du système. Dans le cache sont stockés l'état désiré et l'état actuel. La boucle de contrôle vérifie si ces états sont identiques et modifie l'état actuel du système s'il ne correspond pas à l'état désiré.
Grâce à l'API déclarative et aux contrôleurs, Kubernetes est capable de se restaurer automatiquement (du moins dans la plupart des cas).
Il reste cependant certains challenges à relever afin d'améliorer cette capacité.
Challenges
-
L'état en cache peut différer de celui du monde réel Par exemple, un volume est détaché manuellement sans notification à Kubernetes. Il faut donc un moyen pour accéder au cache, vérifier l'information contenue et la modifier.
-
La cohérence des états (réels, en cache ou désirés) peut prendre beaucoup de temps Par exemple, si un nœud s'éteint, Kubernetes ne va détecter ce changement qu'après 5 minutes, et exécuter les actions nécessaires sur les pods et les volumes qu'après un tel délai.
Une dernière remarque : le self-healing et la haute disponibilité ne sont pas synonymes ! Et Kubernetes propose bien la capacité de self-healing, à vous d'implémenter la haute disponibilité.
Transparent Chaos Testing with Envoy, Cilium and eBPF
Connaissez-vous le Chaos Testing ? C'est une méthode de test qui consiste à injecter volontairement des erreurs dans un système pour estimer sa tolérance à la panne et sa résilience. Cette méthode s'est notamment démocratisée grâce à l'outil Chaos Monkey créé par Netflix en 2011. Par "erreur", on entend par exemple la corruption des messages échangés au sein d'un système, le ralentissement des requêtes ou la modification des codes de retour.
Grâce à l'extensibilité des composants Kubernetes, il est aujourd'hui très simple de simuler une défaillance réseau ou applicative au sein d'un environnement applicatif.
Les prérequis du chaos testing sont les suivants :
- MITM : On doit être en mesure de se placer au cœur des communications inter- services pour en prendre le contrôle
- Capacité de simuler les dysfonctionnement (modifier les codes de retour à la volée par exemple, ou simuler une congestion)
- Capacité de gérer la probabilité de déclenchement des erreurs générées
- Transparence : On ne doit pas avoir besoin de redémarrer ou modifier un service pour tester sa tolérance à l'erreur
- Visibilité : On doit doit être en mesure de savoir immédiatement si on est confronté à une vraie erreur ou à un dysfonctionnement simulé par le chaos testing
Thomas Graf, CTO et co-fondateur de Isovalent et de Cilium, nous démontre ici la simplicité de la mise en place de chaos testing grâce à Envoy (et sa gestion des extensions en Go), Cilium et eBPF.
Pour ceux qui ne le connaissent pas encore, Envoy est :
- un Edge Proxy / Service Proxy qui supporte HTTP/2, gRPC, MongoDB, DynamicDB et bientôt de nombreux autres protocoles
- Un load balancer L7 qui gère de nombreux usages avancés (rate limiting, circuit breaking, retries, canaries...)
- Un service de sécurité gérant mTLS et toute la partie autorisation si besoin
- Un service observable de tracing et de métriques
- Un service extensible en LUA, WASM, Go...
Il permet notamment d'obtenir une distribution du trafic vers différents services comme dans la représentation ci-dessous :
-> (10%) ServiceB v1.5.1-rc12
ServiceA -> Envoy -> (45%) ServiceB v1.4.3
-> (45%) ServiceB v1.4.3
Entre les services à tester et Envoy, Thomas s'appuie sur Cilium. Pour rappel :
- Cilium est basé sur eBPF
- Il gère les communications réseau via le plugin CNI natif Cilium-CNI ou en chaînage par dessus la plupart des autres plugins CNI du marché
- Il implémente le mécanisme des services dans Kubernetes
- Il permet d'appliquer des règles sur le trafic réseau, basées sur la configuration DNS, sur des API ou même en s'appuyant sur la gestion d'identité
- Il permet de chiffrer le trafic et de mettre en place des configurations multi-cluster
- Il peut s'intégrer nativement avec Istio ou Envoy, permettant ainsi une amélioration sensible des performances.
Cilium tire donc profit de eBPF, une sandbox haute performance dédiée au réseau dans le Kernel Linux (~ machine virtuelle) qui a la particularité d'être extensible, tout en conservant les performances et la sécurité. C'est un projet soutenu par Cilium, Facebook et comportant notamment des contributions de Google, RedHat, Netflix, Netronome...
Thomas nous propose une implémentation simple du chaos testing que vous pourrez retrouver sur GitHub. La mise en place est un jeu d'enfant : une simple Network Policy Cilium permet de re-router dans la proportion de son choix le trafic entre deux services vers Envoy avec un profil spécifique. Le profil est configuré pour injecter les erreurs souhaitées via une extension Go de Envoy, en l’occurrence en réponse 504. Un header distinctif est ajouté aux requêtes modifiée et le trafic est renvoyé au service de destination en suivant sa route normale.
Il n'y a plus qu'à surveiller le comportement du système avec les outils de supervision classique pour s'assurer de la tolérance des services à la panne. Pour désactiver le test, il suffit de supprimer la policy Cilium.
A vous de jouer !
The Story of Why We Migrate to gRPC and How We Go About It
- Matthias Grüter, Engineering Manager, Spotify
Cette session est un retour d'expérience de Spotify sur sa migration vers gRPC.
Une brève introduction de l'infrastructure Spotify la décrit comme une entité avec :
- ~2.5k services
- ~1k développeurs
- ~250 équipes
- Java, Python, etc...
Hermes est un protocole développé en interne par Spotify en 2012 et basé sur ZeroMQ afin d'assurer les communications RPC entres les différents services.
Plusieurs raisons sont évoquées pour comprendre ce choix :
- l'écosystème autour de
Hermesest quasi inexistant - l'outil reste très hermétique et difficile à appréhender par les développeurs impactant ainsi le Time To Market
- la difficulté de faire évoluer les structures de données
Le choix de gRPC est dû à :
- Protocol Buffer : il aide à définir une API de service stable et correcte
- le support de plusieurs langages de programmation lors de la génération du code basé sur Protobuf
- sa conception basée sur HTTP/2
- une approche cloud native au cœur de sa conception
- la rétrocompatibilité
- l'extensibilité du schéma de données
Ce changement de paradigme a pour conséquence le changement du schéma de données gérées par Hermès ainsi qu'une réorganisation du code source et des équipes de développement.
gRPC apporte de la résilience grâce des mécanismes comme :
- les retries : définissant le nombre de tentatives effectuées par un appel RPC avant d'échouer
- les deadlines : permettant aux clients gRPC de spécifier le délai d'attente avant la fin d'un appel RPC de façon à ce que l'appel RPC se termine avec l'erreur
DEADLINE_EXCEEDED
Migration
La migration vers gRPC a principalement consisté en :
- évangéliser les différentes équipes de développement sur les avantages du gRPC
- rendre les équipes autonomes donc avoir une culture de confiance dans les équipes
- faciliter l'adoption avec de la génération de code, la mise en place de patterns de résilience, l'intégration d'outils de tracing
- éventuellement forcer les équipes à migrer rapidement lorsqu'elles sont trop longues à migrer
Service Mesh for legacy app
Cette présentation est effectuée par deux ingénieurs de 1&1, un hébergeur d'origine allemande. Le constat est assez simple, malgré une poussée de Kubernetes, des applications stateless, des microservices, (etc.), les applications et infrastructures "legacy" restent présentes et ne peuvent pas être mise de côté. Elles doivent même parfois être intégrées au nouveau monde. La problématique est donc d'apporter de la "cloud compliance" à ces applications legacy sans avoir besoin de les redévelopper. Cette problématique est rencontrée par un nombre important de clients qui souhaitent migrer vers le cloud et les containers, mais ne peuvent pas se permettre de partir from scratch. Les services mesh sont un exemple de service cloud permettant de faciliter cette transition.
Les services mesh sont des composants travaillant au niveau du réseau entre les microservices. Leur travail est d'offloader certaines fonctionnalités traditionnellement portées par les applications elles-mêmes. On pense notamment aux fonctions d'authentification, de chiffrement, de logging, etc. Le chiffrement est un exemple extrêmement courant. Au lieu d'implémenter du TLS, on choisit de ne pas le gérer au niveau de l'application mais d'effectuer le chiffrement au travers de proxies situés juste devant nos microservices. Pour n'importe quel exemple précédent, l'intérêt est de parvenir à une gestion unifiée et centralisée du chiffrement (par exemple) et de l'imposer par défaut à tous nouveaux microservices. Le temps de développement est forcément accéléré. Parmi les autres avantages des services mesh, la maîtrise et le contrôle des flux sont extrêmement importants, car ils permettent d'appliquer différentes stratégies de rolling update ou bien de tests de charge.
Malgré un sujet accrocheur, la présentation s'est surtout contentée de décrire les avantages des services mesh (Istio était utilisé) mais n'est pas rentrée dans le détail de la mise en place avec des applications legacy. Le principal point est la fonctionnalité de mesh expansion d'Istio (>= 1.1) permettant de connecter des serveurs externes (bare metal ou VM) à un réseau mesh situé dans Kubernetes.
Une liste de doléances vis-à-vis de Istio clôture cette session :
- Le control plane tourne en tant que root
- Nécessite un FS en écriture
- Des privilèges élevés sont nécessaires pour faire fonctionner Istio (
NET_ADMINcapability, run as root)
Visually compelling developer experiences for Kubernetes on VS Code
Ivan Towlson (Microsoft) Ralph Squillace (Microsoft)
Qui n'aime pas la ligne de commande ? Tout le monde adore la ligne de commande !
En fait... Ce n'est pas tout à fait vrai. Certains développeurs préfèrent disposer de ces fonctionnalités dans leur éditeur de texte.
It's great that we've built a system that makes it easier to deploy distributed systems, but if we haven't made it possible for **everyone** to use Kubernetes then we have actually failed
Brendan Burns
Cette présentation introduit des fonctionnalités de VSCode ayant pour but de démocratiser l'administration de Kubernetes.
Un bon outil en ligne de commande présente les intérêts suivants :
- la possibilité de découvrir les commandes et les options de façon incrémentale plutôt que dans la doc
- une visualisation des informations claire
- l'adaptation au contexte
Mais, soyons, honnêtes : les outils en command-line ne conviennent pas à tous les utilisateurs, et beaucoup d'entre eux préfèrent la souris et les menus à l'austérité d'un terminal non-solarisé. Après tout, la plupart des grands outils en ligne de commande ont aussi leur version graphique ! Il suffit de penser à git et gitk, par exemple.
Un outil graphique pour administrer Kubernetes est désormais disponible au travers de VSCode, et il faut avouer qu'il semble très pratique.
La puissance d'un clic droit
Contexte aware, version aware, toolchain aware, task aware, ...des qualités à la hauteur des attentes des plus radicaux du terminal d'entre nous. L'extension permet de naviguer très facilement entre les déploiements, namespaces et services, d'éditer les objets à la volée, d'afficher un différentiel entre l'éditeur et la version déployée, de suivre les logs, mettre en place du port-forwarding ou encore d'ouvrir un terminal dans un container... L'éditeur affiche même des tooltips explicatifs sur les clés des YAML de manifests. Il fonctionne aussi avec Helm (gestionnaire de paquets de Kubernetes).
Quelques screenshots pour vous convaincre :
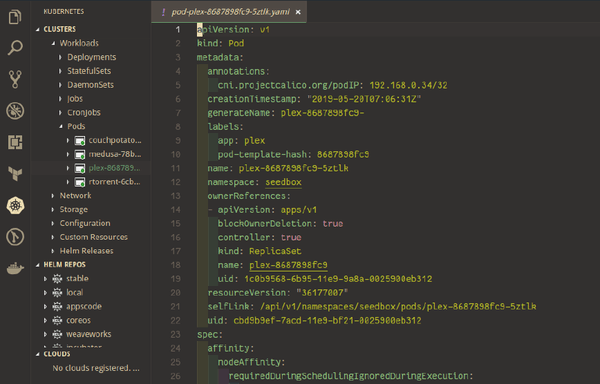
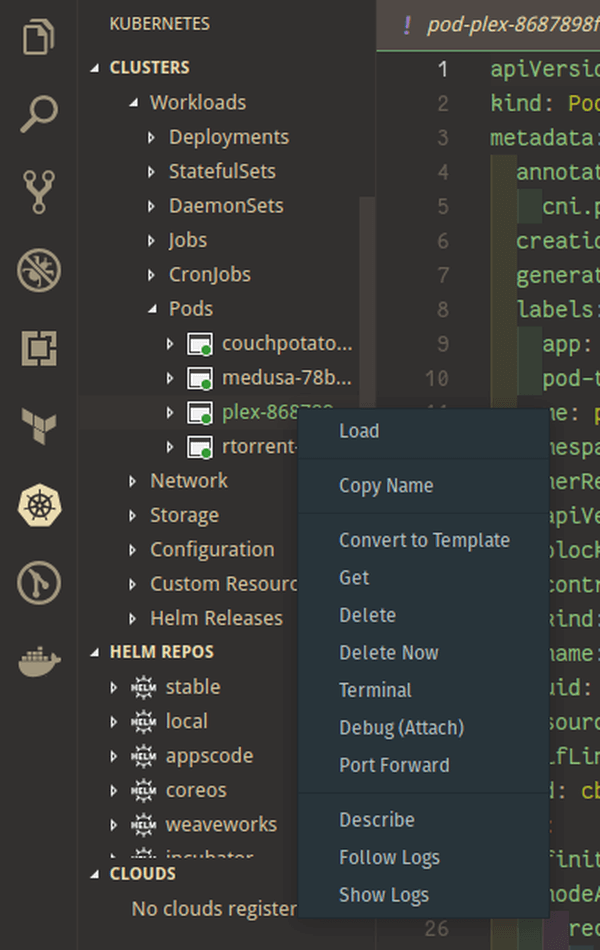
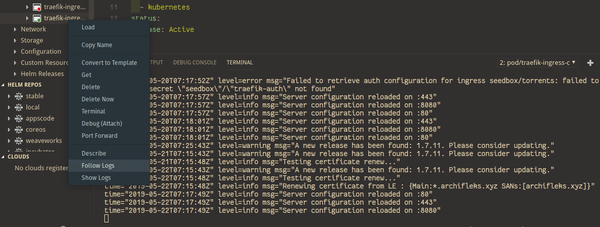
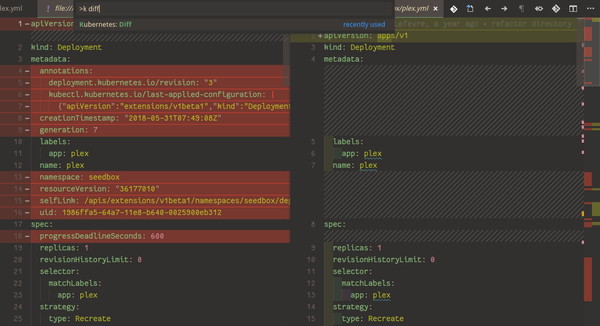
Pour terminer, quelques outils utiles (CLI mais compatibles VSCode) que nous vous conseillons d'utiliser :
- Krew : le gestionnaire de paquets pour les plugins kubectl.
- Rakkess : un outil qui montre la matrice d'accès pour les ressources du serveur.
- Stern : un outil qui permet de récupérer les logs de plusieurs pods en même temps.
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025



