
Après Londres, nous voici à Genève pour OpenStack Day ... CERN.
En effet, le CERN est un utilisateur emblématique d'OpenStack, et leur rôle important dans la communauté n'est plus à démontrer. Cette journée étant organisée et hébergée par le CERN, avec un focus sur les sujets scientifiques, il s'agit bien d'OpenStack Day CERN, plutôt qu'OpenStack Day Geneva. :-)
Plus d'informations sur le site officiel.
#OpenStackDayCERN
— Awatif AW (@Awatif__AW) 27 mai 2019
Notre équipe @alterway Cloud Consulting vous prépare un résumé, de cet événement dédié à #OpenStack et sa contribution dans l’accélération de la science 🔬, (qui se déroule actuellement à Genève). Bientôt sur notre blog 👉https://t.co/W6NBznqiWB pic.twitter.com/2srAGCDDwo
La journée se déroule dans l'amphithéâtre dans lequel a - notamment - été annoncée la découverte du boson de Higgs. Cadre plutôt sympathique !
Jonathan Bryce, directeur exécutif de la Fondation OpenStack, ouvre l'événement. Il établit un parallèle très intéressant entre le modèle de collaboration ouverte et internationale du CERN et celui ... d'OpenStack.
Dès les premières conférences, les visiteurs sont mis dans le bain scientifique : on s'intéresse plus aux cas d'usages qu'à OpenStack en tant que tel : cela permet de prendre un peu de recul, et de voir comment la technologie participe à des avancées largement plus grandes que nous.
On parle du CERN bien évidemment, avec ses plus de 270000 cores CPU gérés avec OpenStack. En effet, il faut une certaine capacité de calcul pour traiter les incroyables quantités de données générées par les expérimentations du LHC.
Un autre projet scientifique est abordé : le radiotélescope Square Kilometre Array (SKA). Son échelle gigantesque nécessite de prévoir une infrastructure IT non négligeable dans laquelle OpenStack a là aussi son rôle à jouer.
Toujours lors de cette matinée scientifique, la NASA est également présente. Co-fondateur d'OpenStack avec Rackspace (pour rappel, Rackspace a amené Swift, alors que la NASA a amené Nova), même si d'autres technologies cloud ont été et sont encore utilisées dans certains domaines, la NASA continue de faire usage de la solution de cloud open source.
After a great #OpenStack + Science day, an underground visit to the LHC ALICE experiment, thanks @CERN! pic.twitter.com/4uciep878o
— Adrien Cunin (@Adri2000_OS) 28 mai 2019
GPU & Nova
Par Sylvain Bauza, Red Hat
Nous avions déjà parlé de ce sujet lors de notre article de la deuxième journée du summit de Denver, mais cet OpenStack Day dédié à la science était l'occasion de refaire le point sur l'utilisation des GPU dans les instances lancées sur une plateforme OpenStack. Ce sujet est d'autant plus pertinent dans le monde de la recherche, très consommateur de GPUs.
Il existe plusieurs façons d'utiliser les GPU dans les instances :
- PCI-passthrough : supporté dans Nova depuis Havana, l'instance accède directement au GPU. Si plusieurs GPUs sont disponibles sur l'hôte, différentes instances peuvent s'allouer un des GPUs. Toutefois, il n'y a pas de mutualisation, le capacity planning est complexe, ainsi que la gestion de la sécurité (flash du firmware possible depuis l'instance, overclocking, etc).
- SR-IOV : supporté dans Nova depuis Juno, les fonctions virtuelles des périphériques permettent une utilisation plus souple des GPUs. Toutefois, les fonctions sont limitées, complexes à mettre en place et disponibles que sur certains types de matériels.
- vGPUs : supportés depuis Queens, les vGPUs sont comparables aux vCPUs des CPUs. Avec ce mécanisme, il est possible de sortir du 1 pour 1, 1 GPU pour 1 instance. Il s'agit ni plus ni moins que de virtualisation de GPU. Ces techniques s'appuient sur des drivers spécifiques, comme Intel GVT-9 ou Nvidia GRID, disponibles sur certains hardwares comme les produits Tesla ou Volta pour Nvidia.
Le Tracing dans OpenStack
Par Ilya Shakhat, Huawei
Ilya Shakhat nous a présenté les avantages et l'outillage autour du tracing dans Openstack. Le tracing consiste à observer facilement toutes les étapes nécessaires à la réalisation d'une action demandée par l'utilisateur. Par exemple, la création d'une instance va nécessiter à l'endpoint Nova de faire des appels au scheduler, qui lui même va solliciter la base de données... Le tracing permet de voir ces étapes au moment où elles se produisent : on évite de devoir faire un travail de devinettes ou de lecture de code fastidieuse.
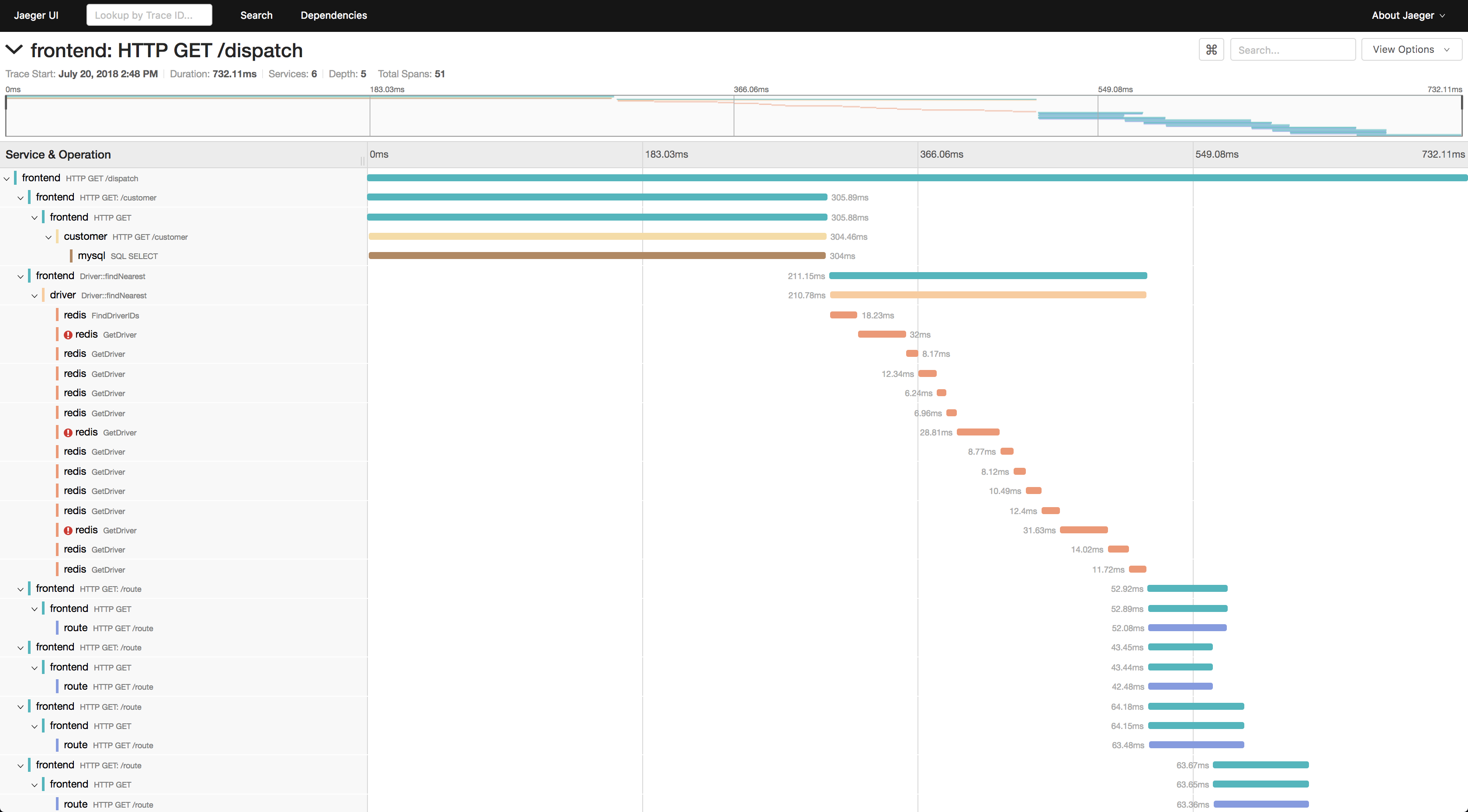 Exemple du rendu d'un appel de démo issu de la documentation de Jaeger
Exemple du rendu d'un appel de démo issu de la documentation de Jaeger
Ceci est très pratique pour faire du root cause analysis, de l'analyse de performances, ou même simplement de comprendre les dépendances inter-services.
Le logging des traces est possible grâce à OSProfiler, celles-ci sont ensuite collectées et processées par Jaeger, un projet de la CNCF.
Un grand merci au @CERN aux organisateurs de l'#openstackdayCERN pour la visite d'Alice au #LHC.
— Pierre Freund (@PierreFreund_AW) 28 mai 2019
16m de haut, 25m de profondeur, 10000 tonnes, plus lourd que la #TourEiffel ! pic.twitter.com/f6ihoDFlpn
Découvrez les derniers articles d'alter way
- J'ai les kro
- J'ai voulu gérer les certificats TLS dans mes clusters KubeVirt. Surprise
- J'ai voulu faire du kubectl top dans mon cluster KubeVirt. L'univers a refusé
- J'ai voulu exposer mes clusters KubeVirt sur Internet. J'aurais dû m'en douter
- J'ai voulu faire du Kubernetes dans Kubernetes
- Industrialiser le RAG pour booster l’IA générative : l’approche pragmatique en 2025


